【InternLM 实战营第二期-笔记3】茴香豆:搭建你的 RAG 智能助理
书生·浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,很高兴能参与本次第二期训练营,我也将会通过笔记博客的方式记录学习的过程与遇到的问题,并为代码添加注释,希望可以帮助到你们。
记得点赞哟(๑ゝω╹๑)
茴香豆:搭建你的 RAG 智能助理
视频教程网址:茴香豆:搭建你的 RAG 智能助理_哔哩哔哩_bilibili
github教程网址:文档地址
作业笔记提交地址
RAG内容介绍
大模型的训练时间在前,无法解答针对新增知识的问题,如何解决大模型的幻觉?
- 传统方法:采集新增语料,通过微调等方式对模型进行再训练。
- 缺陷:知识新增太快,语料太多,语料难以收集,训练成本太大。
针对此问题改进:
rag技术的提出。(不需要训练,解决新增知识的问题)

定义
Rag(retrieval augmented generation)是一种结合了检索(retrieval)和生成(generation)的技术,旨在通过利用外部知识库来增强大型语言模型(llms)的性能。它通过检索与用户输入相关的信息片段,并结合这些信息来生成更准确,更丰富的回答。
可以理解为一种搜索引擎,将用户输入内容作为索引,在外部知识库中搜寻到内容,结合大语言模型进行回答
解决LLMs在处理知识密集型任务时可能遇到的挑战:
- 生成幻觉(hallucination)
- 过时知识
- 缺乏透明和可追溯的推理过程
提供更准确的回答、降低成本,实现外部记忆。
RAG工作原理
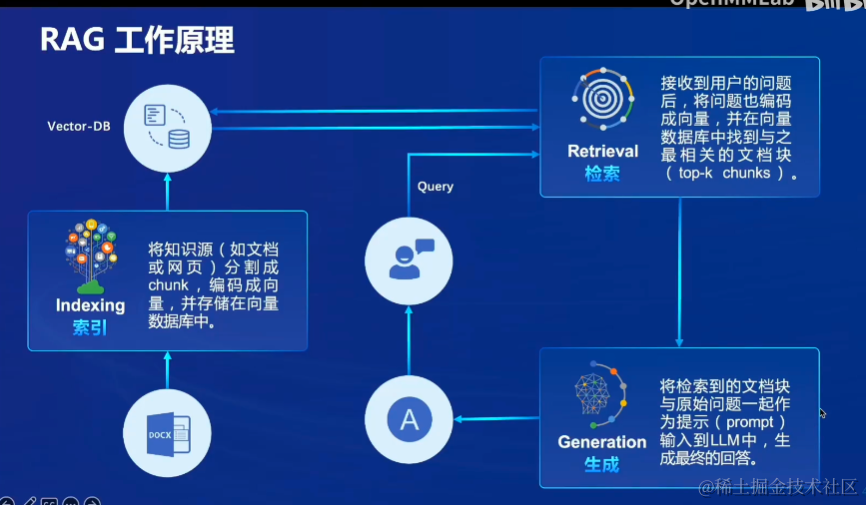
索引indexing——检索Retrival ——生成Generation
-
索引indexing:知识源处理,(如文档、网页)分割成chunk,编码成向量,存储在向量数据库中。
-
检索Retrival :输入问题处理,接收用户问题编码为向量,在向量数据库之间找到与之最相关的文档块(top-k chunks)。
-
生成Generation:答案生成, 将检索到的外挂信息与原始问题一起作为提示,输入LLM中,得到最终的回答。
向量数据库(Vector-DB)

数据存储: 将文本及其他数据通过其他预训练的模型转换为固定长度的向量表示,这些向量能够捕捉文本的语义信息。
相似度检索: 根据用户的查询向量,使用向量数据库快速找出最相关的向量的过程。通常通过计算余弦相似度或其他相似性度量来完成。检索结果根据相似度得分进行排序,最相关的文档将被用于后续的文本
生成。
向量表示的优化: 包括使用更高级的文本编码技术,如句子嵌入或段落嵌入,以及对数据库进行优化以支持大规模向量搜索。
RAG流程示例
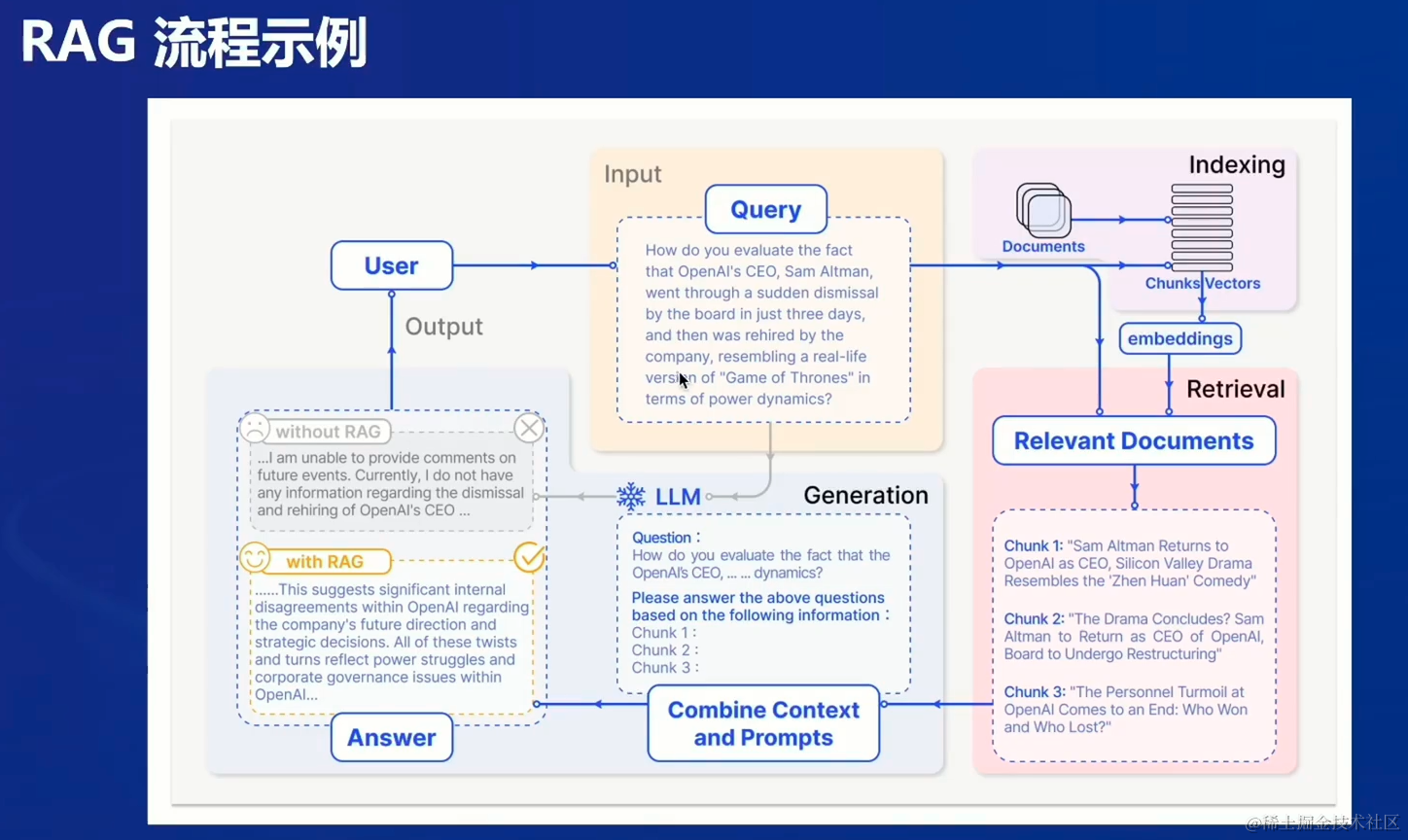
为了解决大模型的时效性问题,RAG给出了如下的解决方案:
- 检索模块将用户的问题向量化,与数据库进行相似度匹配,
- 找出匹配度最高的Chunks,
- 将问题与chunks一起返回给生成模块,形成prompt
- 生成自然语言答案返回给用户。
- 实效性数据则需要不断更新知识库,实现及时补充最新版知识。
RAG发展进程

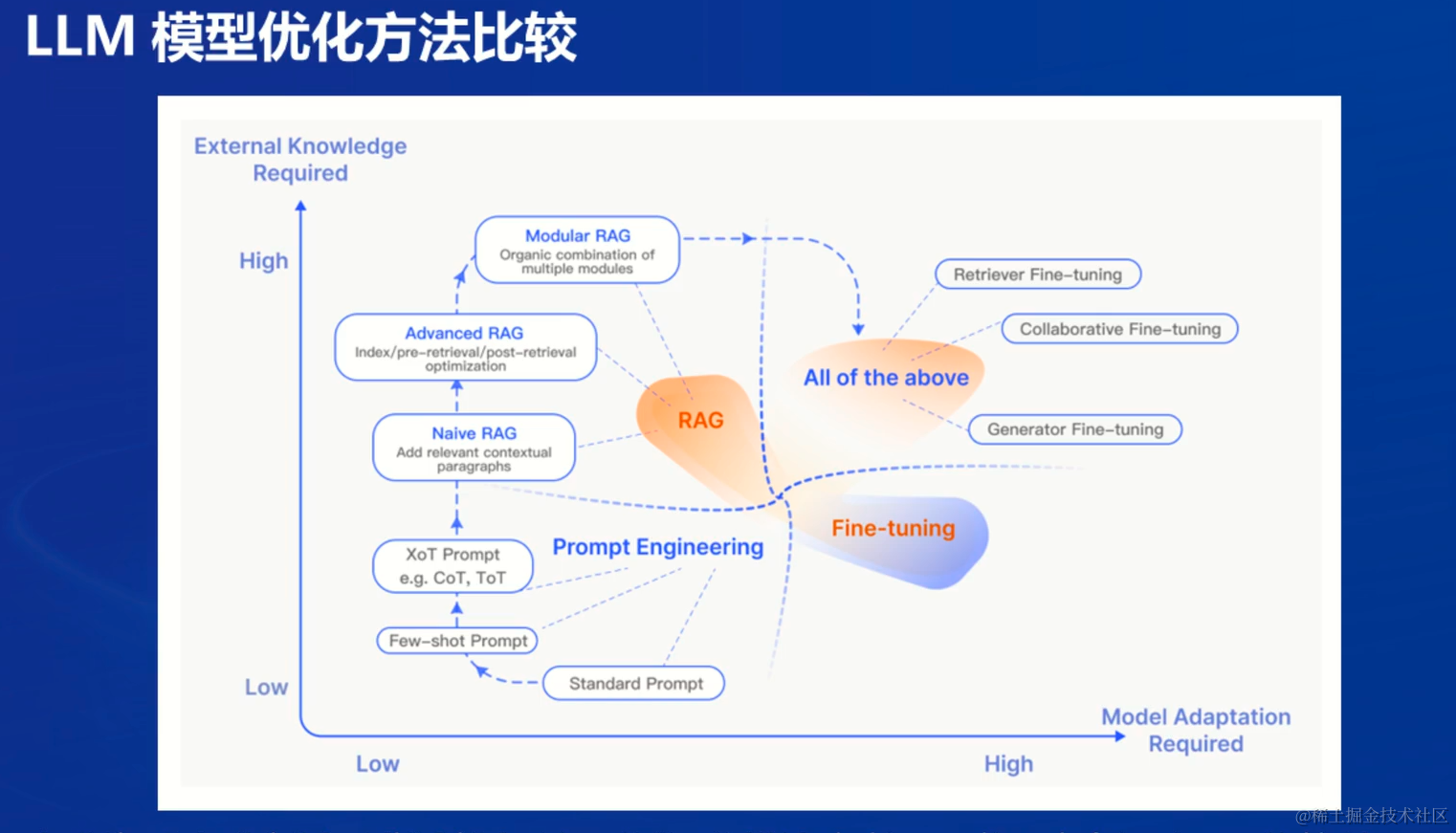
三种RAG的范式:
- Naive RAG: 即索引,检索,生成三部分构成的最基本的泛式, 这种范式经常用于简答的问答系统和信息检索场景中
- Advanced RAG: 在三个基础部分之外对检索前后都进行了增强,在检索之前对用户的问题进行路由,扩展,重写等处理, 在检索到的内容进行重排序,总结。融合等处理,是信息收集和处理效率更高。常用于摘要生成,内容推荐场景
- Modular RAG: 将RAG的基础部分和后续的各种优化技术和功能模块化,可以根据实际需求定制,可以完成多模态任务和对话系统
RAG常见优化方法

- 提高向量数据的质量:
- 嵌入优化(embeding_opyimization)
- 结合稀疏和密集检索;
- 多任务
- 索引优化(indexingOPtimization)
- 细粒度分割(chunk)
- 元数据
- 查询优化(QueryOPtimization)
- 查询扩展、转换
- 多查询
- 上下文管理
- 重排(rerank)
- 上下文选择/压缩
- 嵌入优化(embeding_opyimization)
- Retrival优化
- 迭代检索(Interactive Retrieval)
- 根据初始查询和迄今为止生成的文本进行重复查询
- 递归检索(Recursive Retrival)
- 迭代细化搜索查询;
- 链式查询(chain—of-thought)指导检索过程
- 自适应检索(Adaptive Retrival)
- Flare、Self-RAG;
- 使用LLMs 主动决定检索的最佳时机和内容)
- 迭代检索(Interactive Retrieval)
- LLM微调(LLM Fine—tuning) 检索微调、生成微调、双重微调
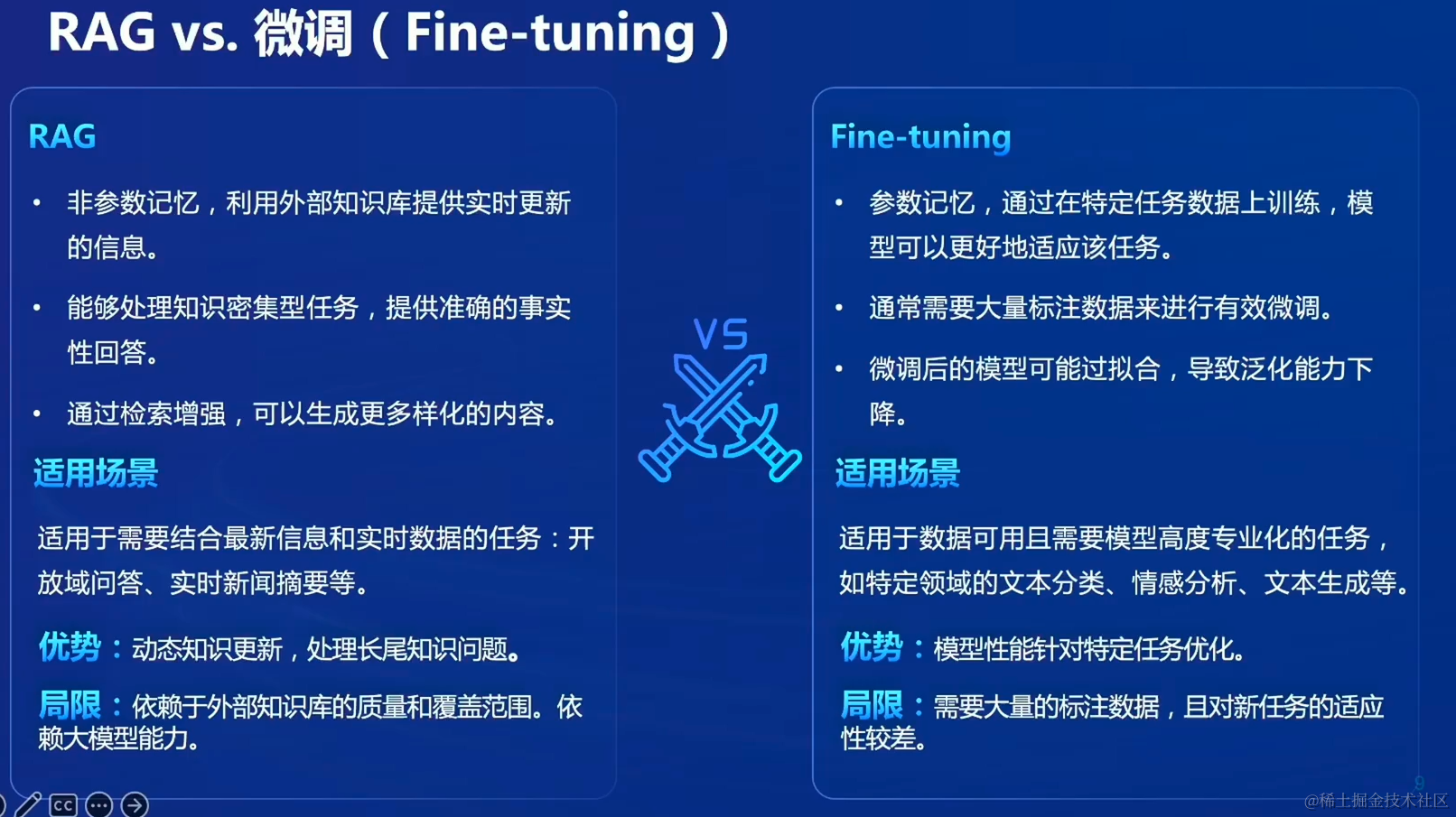
RAG vs.微调(Fine-tuning)
大模型常用优化方法比较
评估框架和基准测试
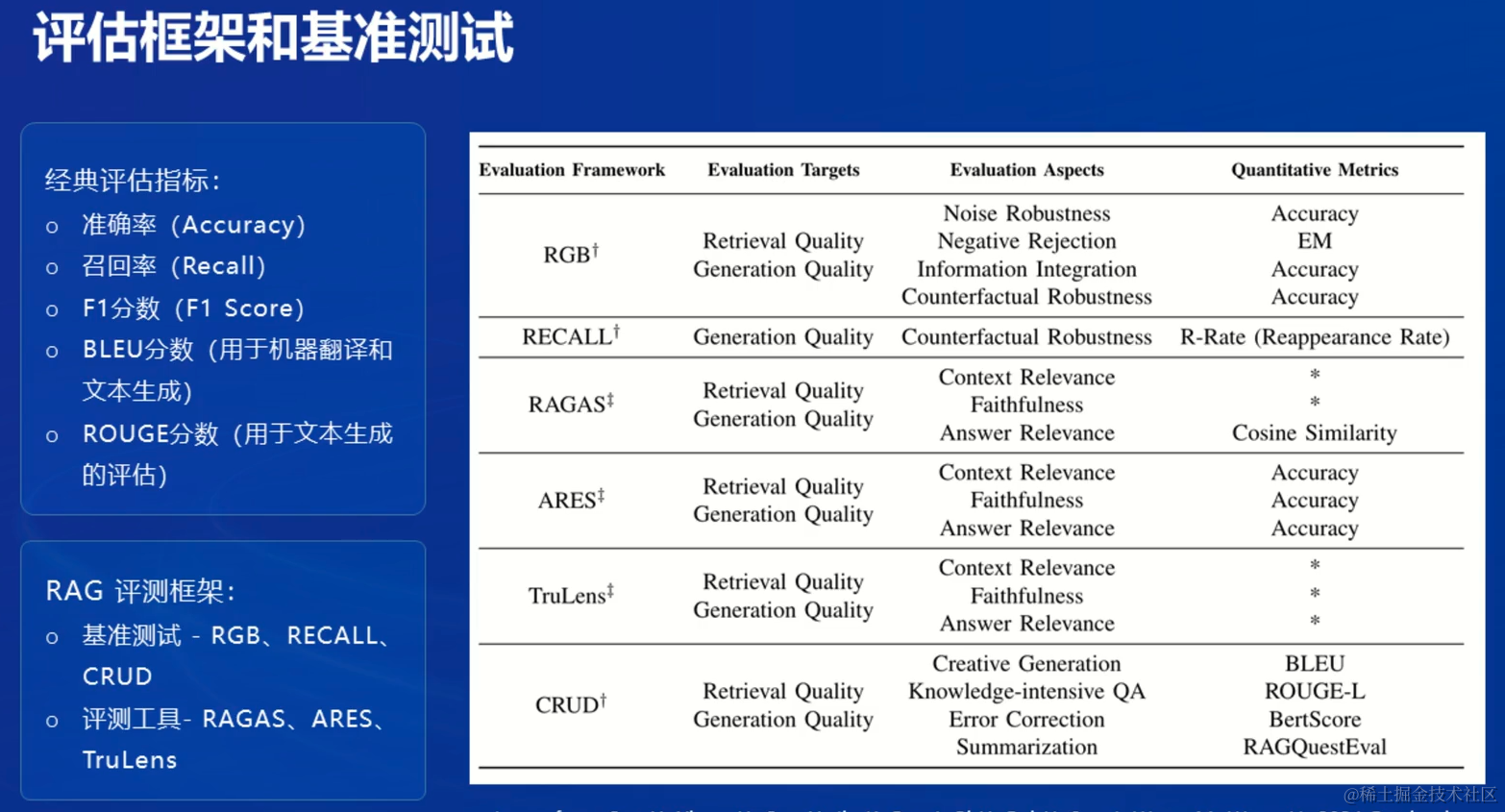
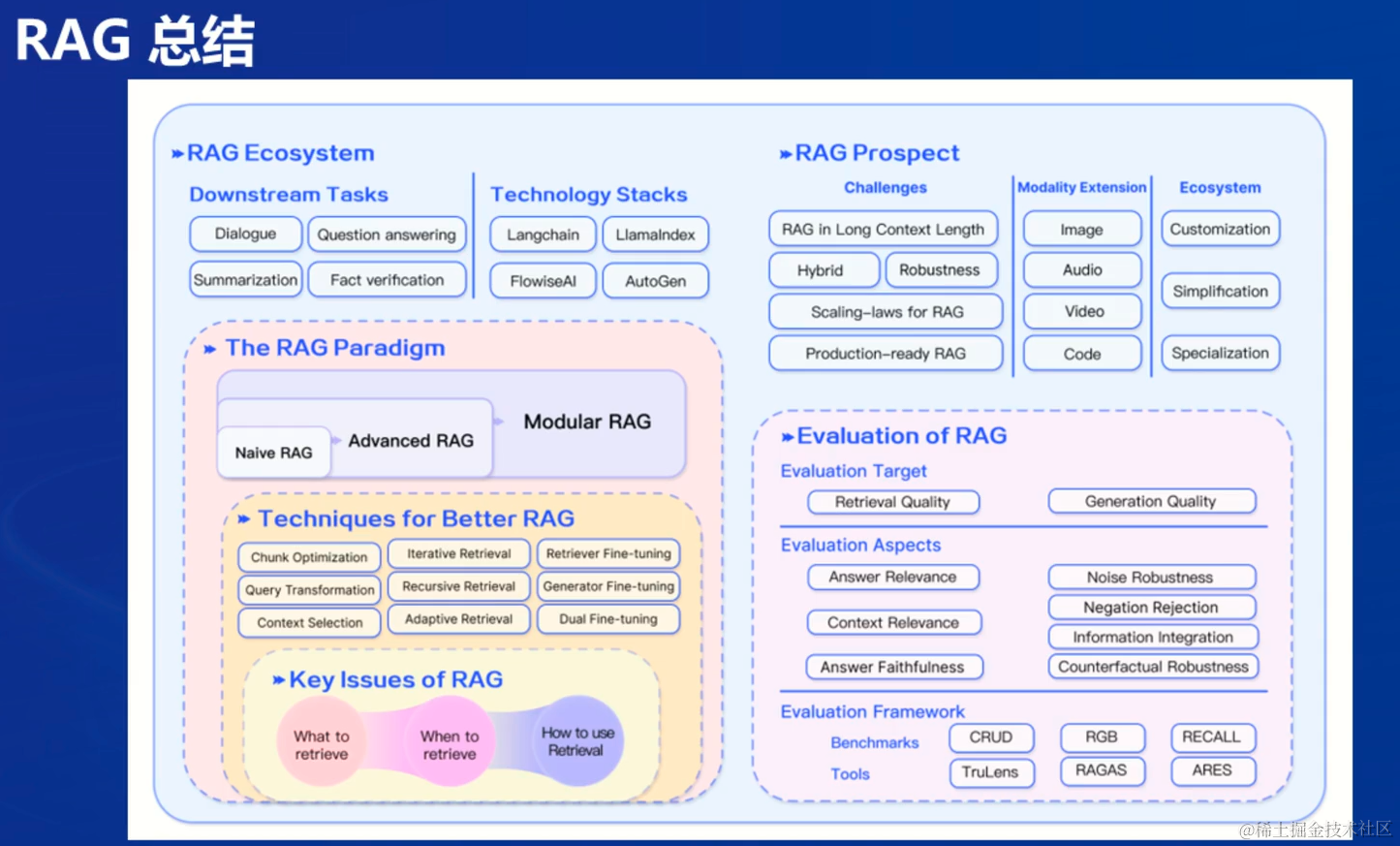
RAG总结
茴香豆

茴香豆(豆哥)介绍

茴香豆的核心特性

茴香豆构建
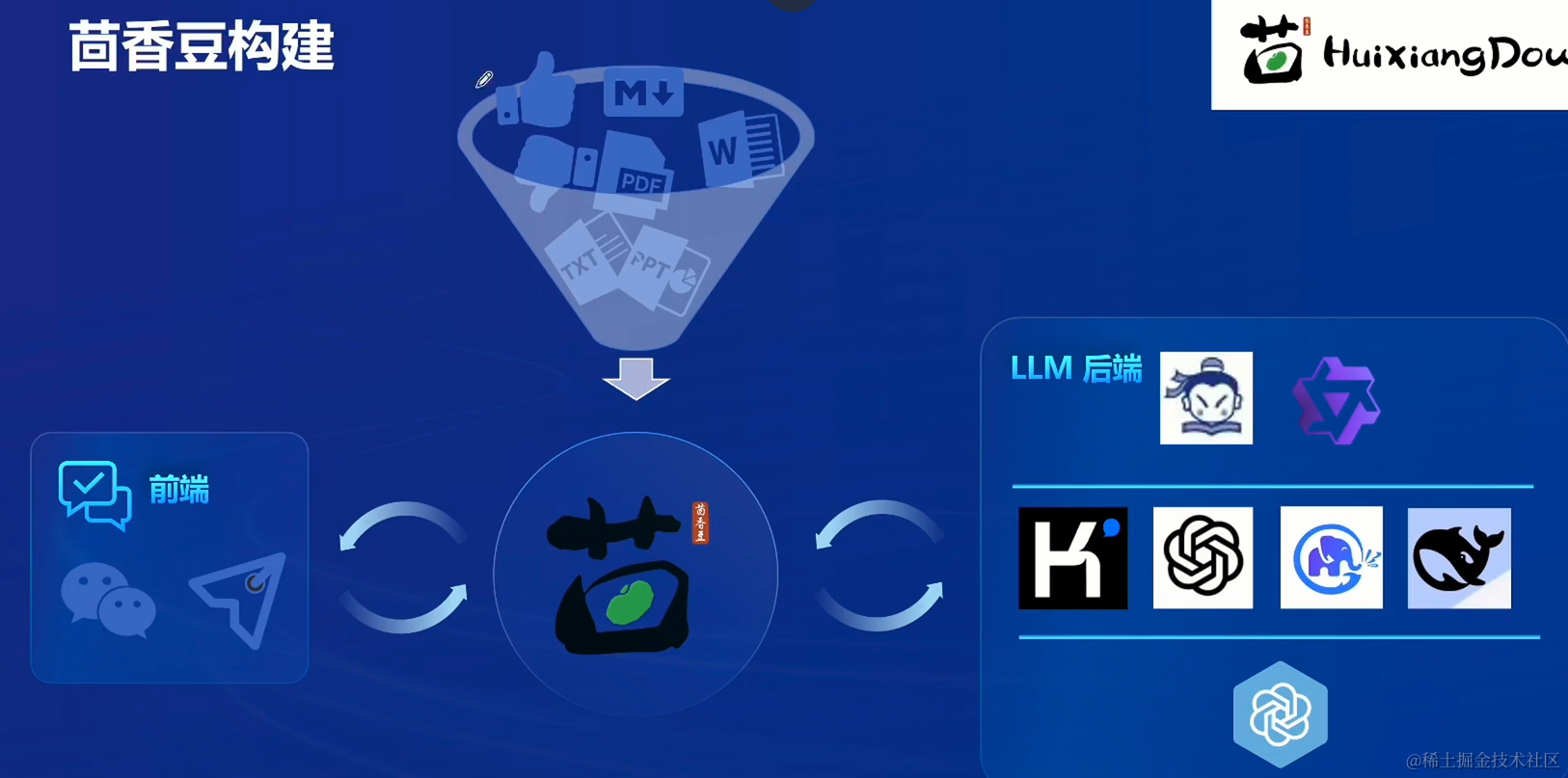
- 茴香豆的知识库构建通常是个人与企业的相关技术知识文档,目前支持Markdown文件、word文档、ppt文件等常用的文件类型,可以设置积极和消极的标签控制助手的回答范围。
- 茴香豆读取用户问题以及相关文档的平台,在国内一般是微信群和飞书群,国外是discord和slack等技术交流应用软件。 茴香豆目前支持调用本地或远端大模型的API,如书生浦语、通义千问、ChatGPT。Kimi等
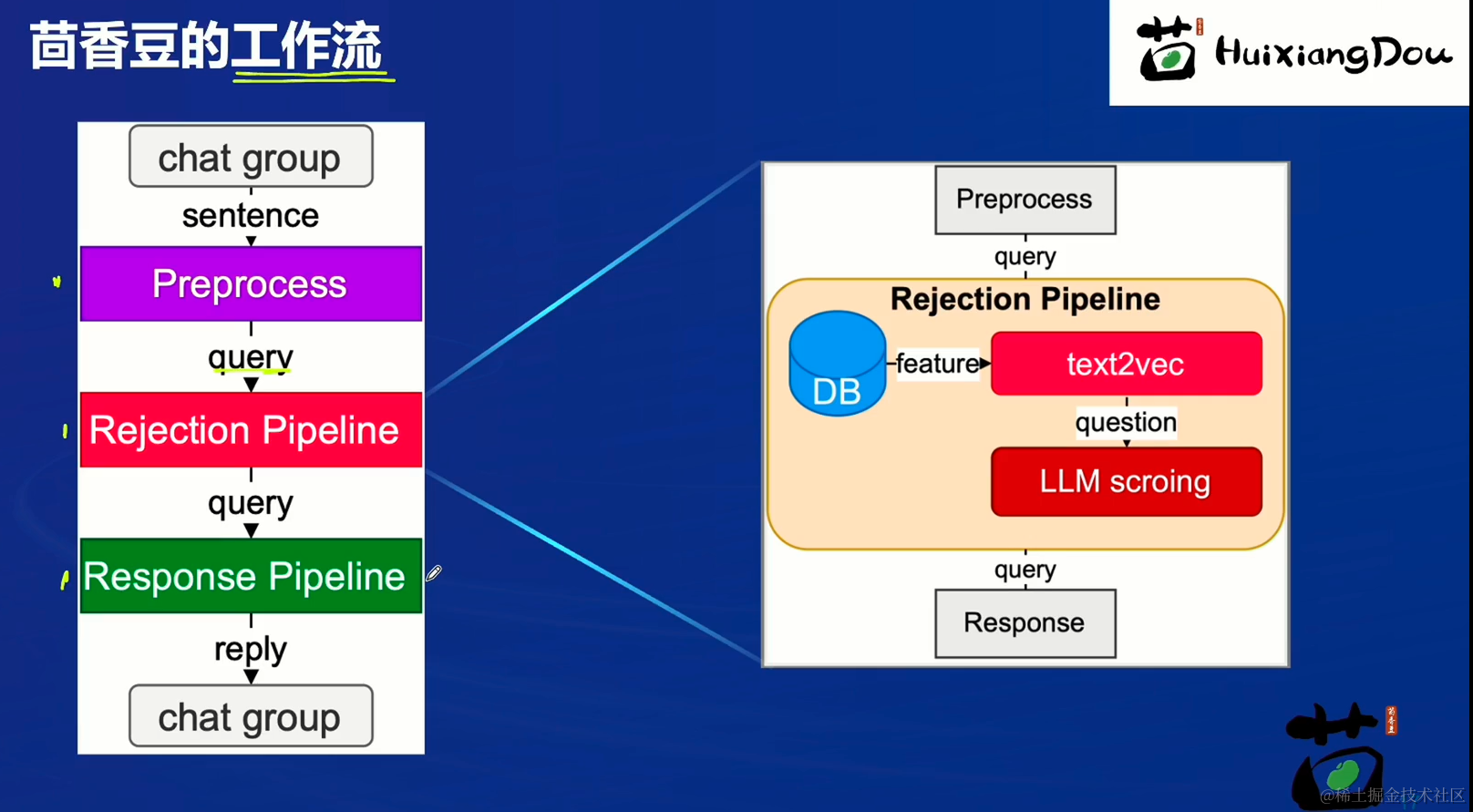
茴香豆的工作流
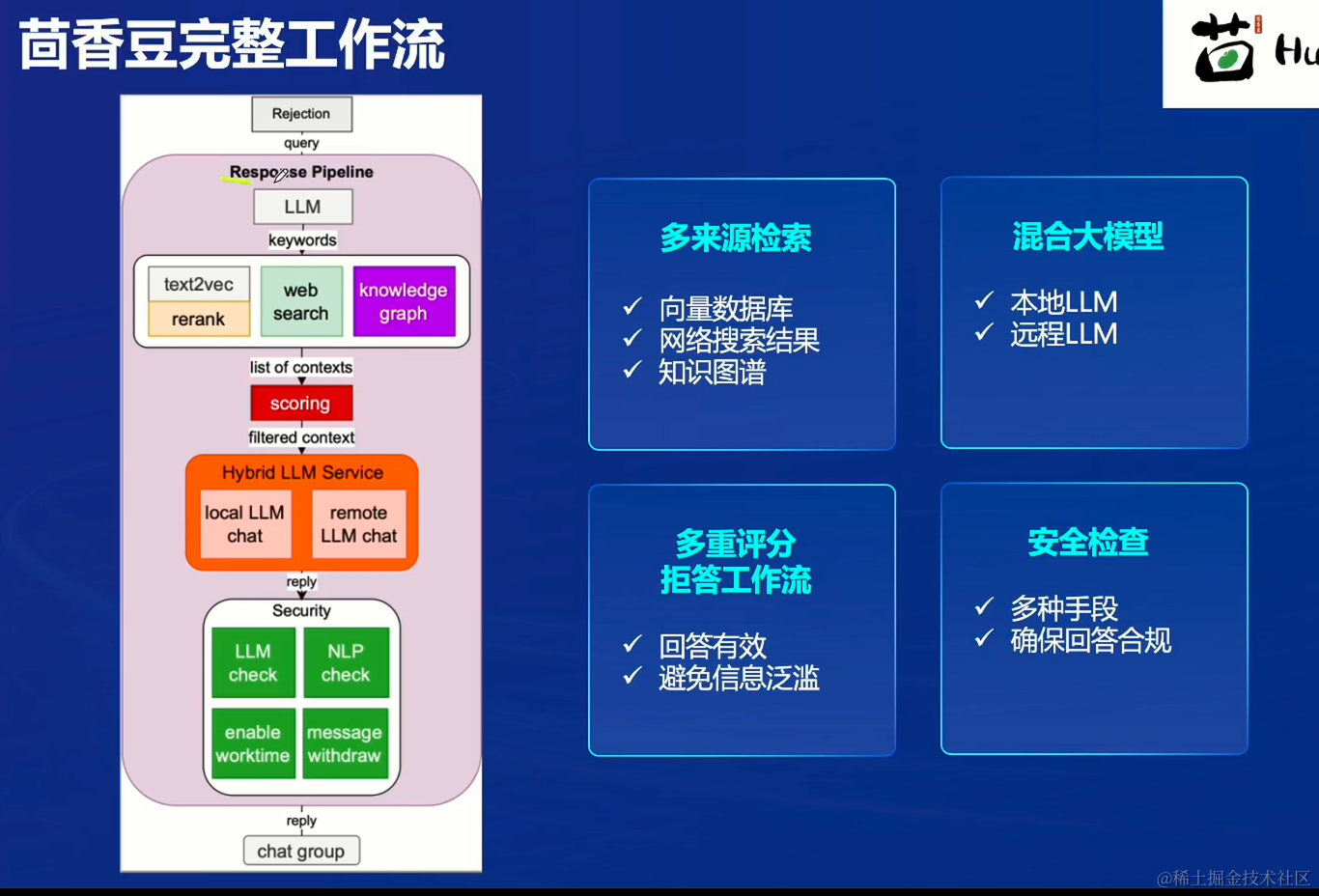
应用茴香豆web版创建属于自己的知识领域回答助手
茴香豆web版链接
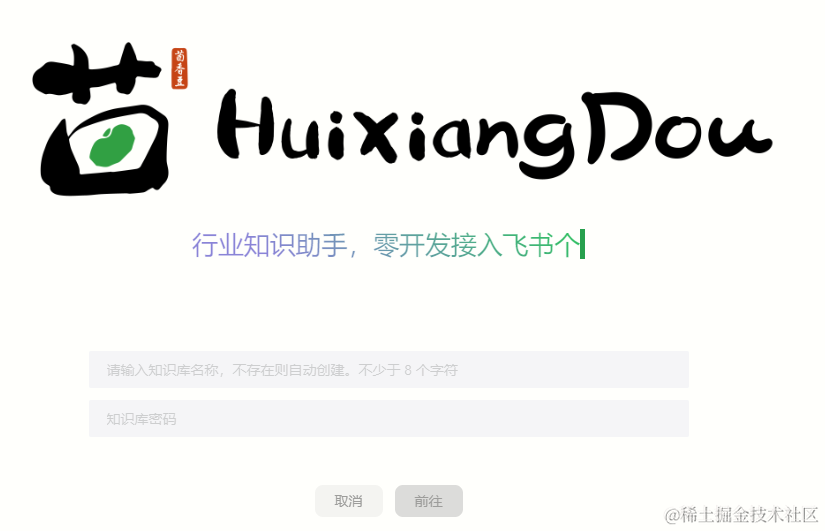
在这个页面创建知识库(名称密码可以随意)
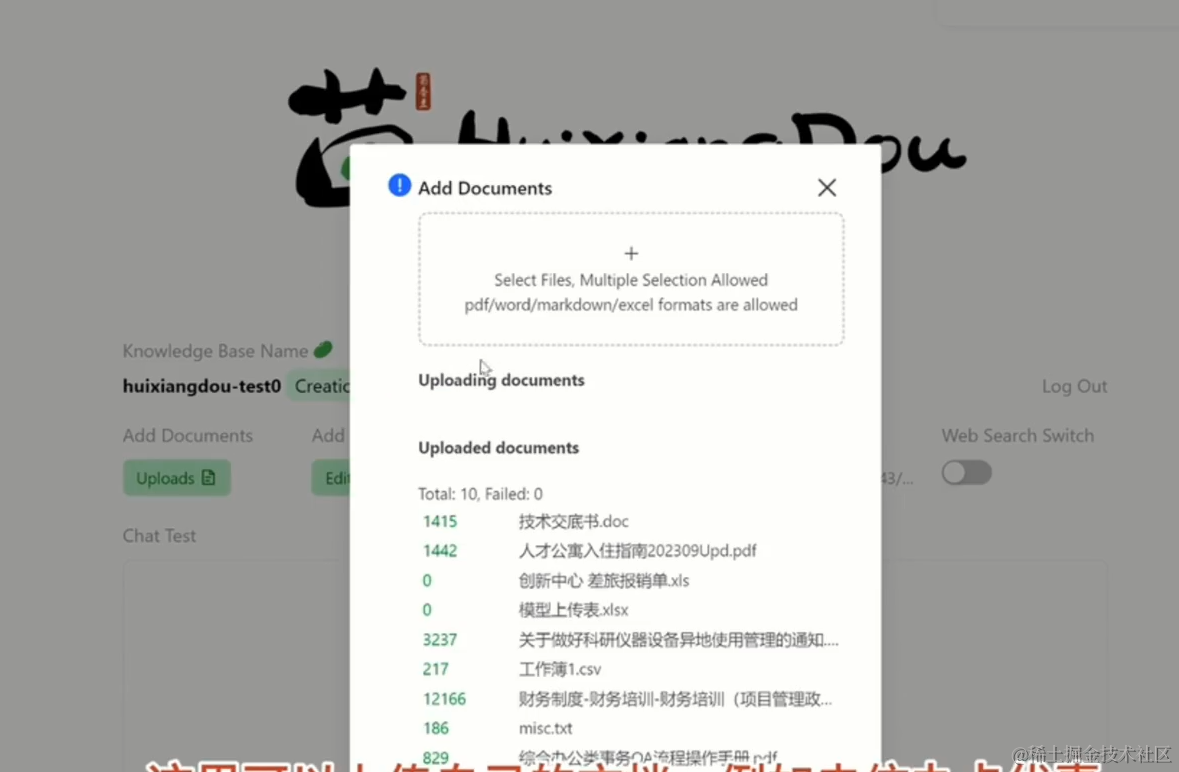
随后上传文档
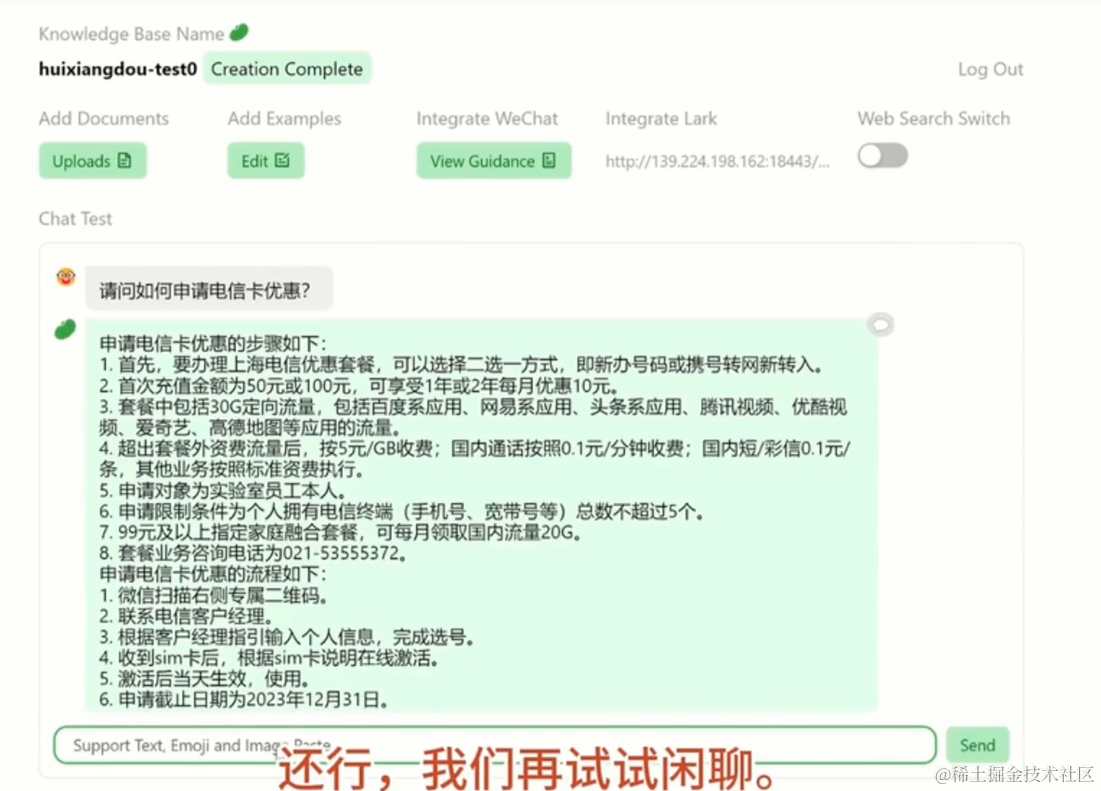
然后就可以提问啦,可以设置问题回答模板,以及拒绝回答的问题样例。并且可以直接部署到飞书,微信等多个平台
这边使用了查单模拟器的官方文档进行测试,效果还是非常棒的,除了抽象肢体上的理解还有些偏差意外,搜索能力已经非常完善了
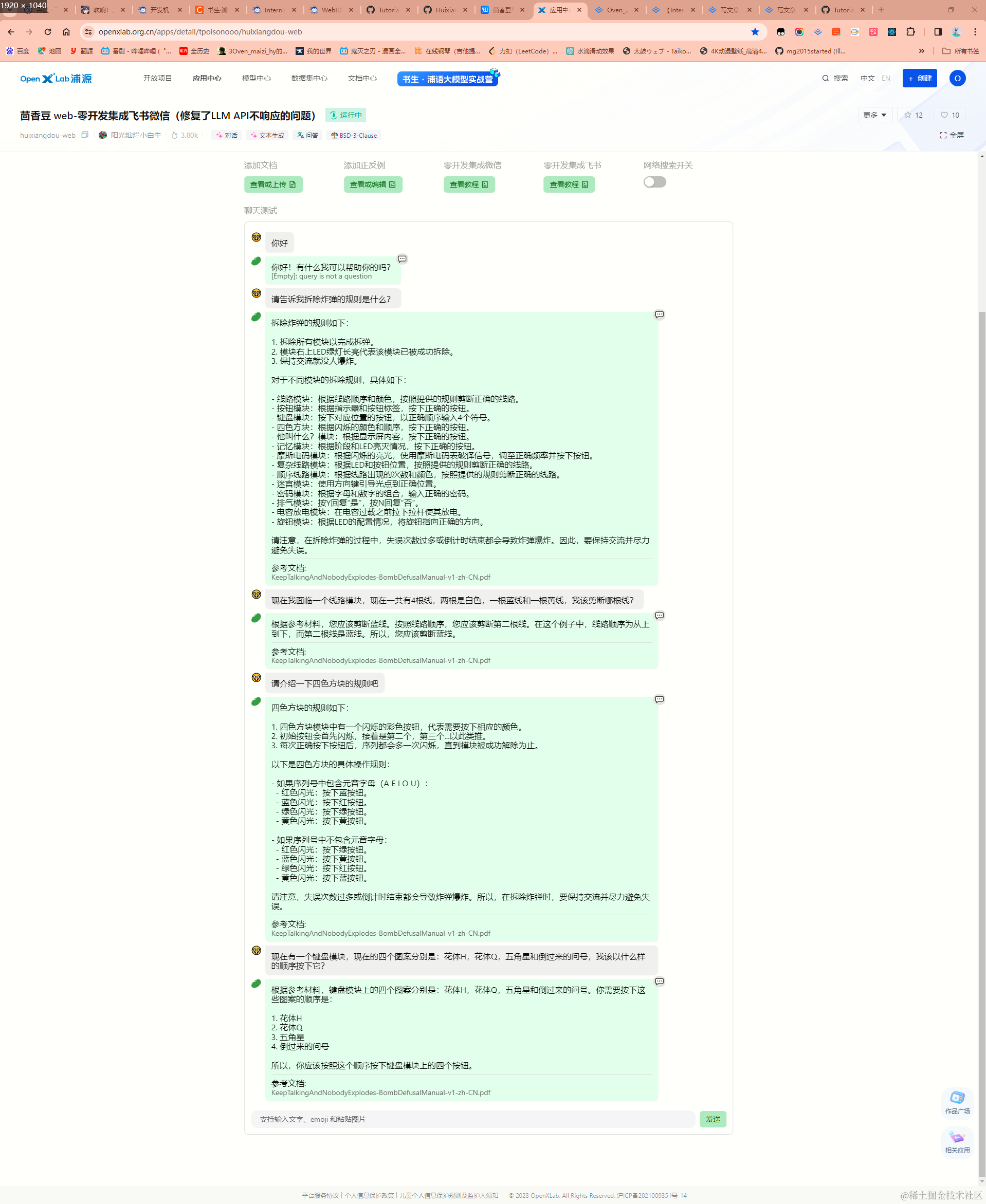
茴香豆部署实战
注意:当前项目需要30%配额
1 环境配置
1.1 配置基础环境
这里以在 Intern Studio 服务器上部署茴香豆为例。
首先,打开 Intern Studio 界面,点击 创建开发机 配置开发机系统。
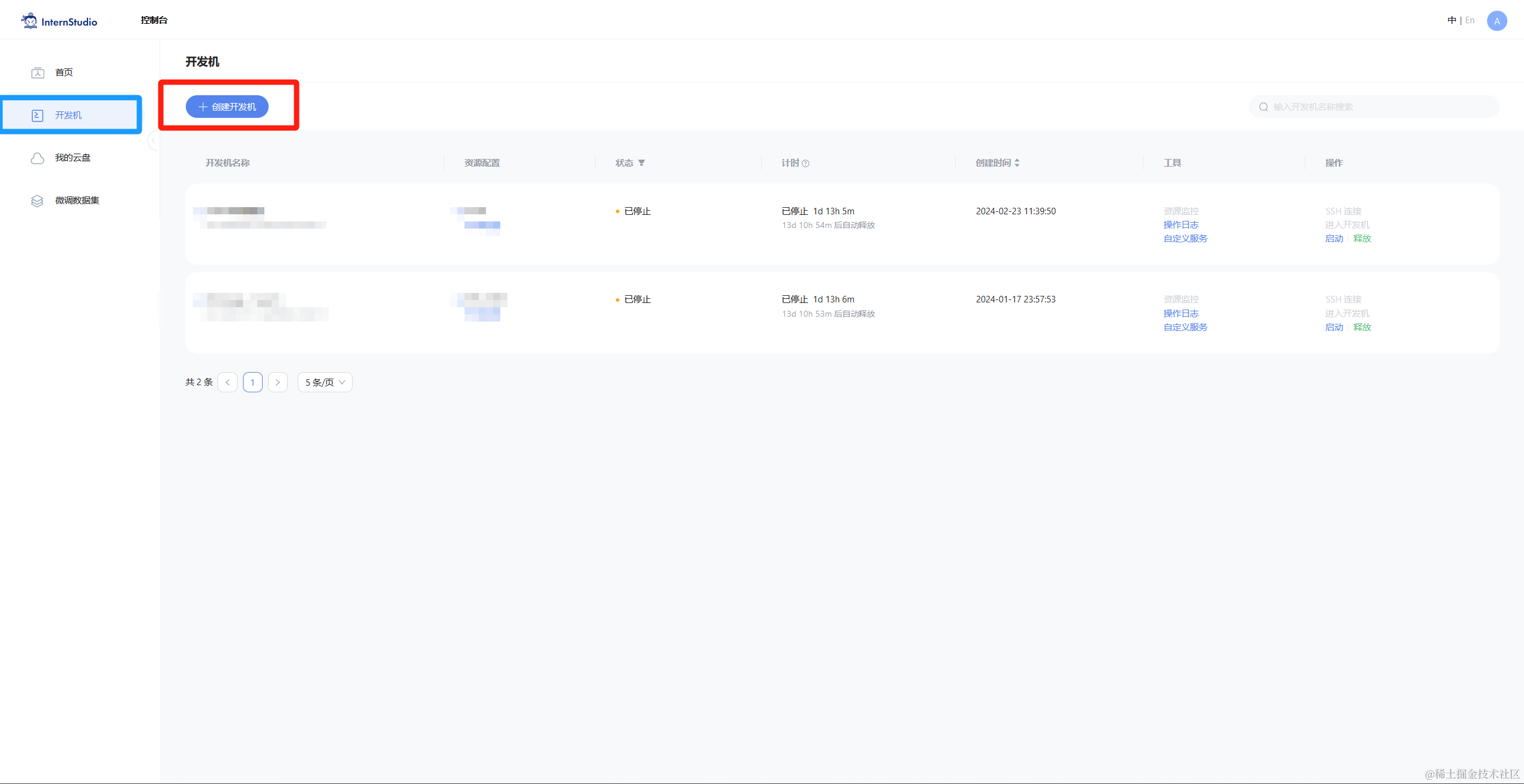
填写 开发机名称 后,点击 选择镜像 使用 Cuda11.7-conda 镜像,然后在资源配置中,使用 30% A100 * 1 的选项,然后立即创建开发机器。

点击 进入开发机 选项。
进入开发机后,从官方环境复制运行 InternLM 的基础环境,命名为 InternLM2_Huixiangdou,在命令行模式下运行:
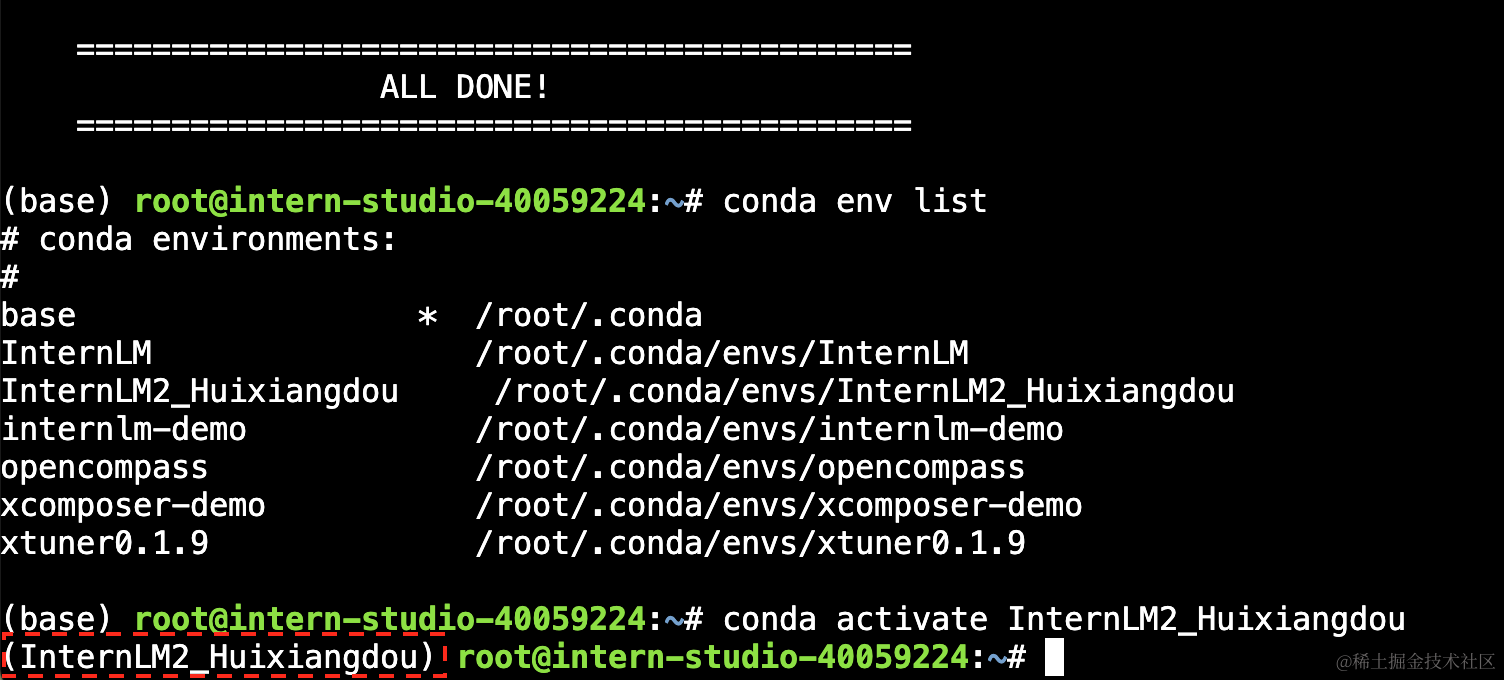
studio-conda -o internlm-base -t InternLM2_Huixiangdou复制完成后,在本地查看环境。
conda env list结果如下所示。
# conda environments:
#
base * /root/.conda
InternLM2_Huixiangdou /root/.conda/envs/InternLM2_Huixiangdou
运行 conda 命令,激活 InternLM2_Huixiangdou python 虚拟环境:
conda activate InternLM2_Huixiangdou环境激活后,命令行左边会显示当前(也就是 InternLM2_Huixiangdou)的环境名称,如下图所示:
后续教程所有操作都需要在该环境下进行,重启开发机或打开新命令行后要重新激活环境。
1.2 下载基础文件
复制茴香豆所需模型文件,为了减少下载和避免 HuggingFace 登录问题,所有作业和教程涉及的模型都已经存放在 Intern Studio 开发机共享文件中。本教程选用 InternLM2-Chat-7B 作为基础模型。
# 创建模型文件夹
cd /root && mkdir models# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b注意:如果这边报错ln: failed to create symbolic link ‘xxx’: Read-only file system 是正常的,因为第一节课已经链接过一次了,而多次链接就会显示无写入权限的问题
1.3 下载安装茴香豆
安装茴香豆运行所需依赖。
# 安装 python 依赖
# pip install -r requirements.txtpip install protobuf==4.25.3 accelerate==0.28.0 aiohttp==3.9.3 auto-gptq==0.7.1 bcembedding==0.1.3 beautifulsoup4==4.8.2 einops==0.7.0 faiss-gpu==1.7.2 langchain==0.1.14 loguru==0.7.2 lxml_html_clean==0.1.0 openai==1.16.1 openpyxl==3.1.2 pandas==2.2.1 pydantic==2.6.4 pymupdf==1.24.1 python-docx==1.1.0 pytoml==0.1.21 readability-lxml==0.8.1 redis==5.0.3 requests==2.31.0 scikit-learn==1.4.1.post1 sentence_transformers==2.2.2 textract==1.6.5 tiktoken==0.6.0 transformers==4.39.3 transformers_stream_generator==0.0.5 unstructured==0.11.2## 因为 Intern Studio 不支持对系统文件的永久修改,在 Intern Studio 安装部署的同学不建议安装 Word 依赖,后续的操作和作业不会涉及 Word 解析。
## 想要自己尝试解析 Word 文件的同学,uncomment 掉下面这行,安装解析 .doc .docx 必需的依赖
# apt update && apt -y install python-dev python libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig libpulse-dev从茴香豆官方仓库下载茴香豆。
cd /root
# 下载 repo
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout 447c6f7e68a1657fce1c4f7c740ea1700bde0440茴香豆工具在 Intern Studio 开发机的安装工作结束。如果部署在自己的服务器上,参考上节课模型下载内容或本节 3.4 配置文件解析 部分内容下载模型文件。
2 使用茴香豆搭建 RAG 助手
2.1 修改配置文件
用已下载模型的路径替换 /root/huixiangdou/config.ini 文件中的默认模型,需要修改 3 处模型地址,分别是:
命令行输入下面的命令,修改用于向量数据库和词嵌入的模型
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini用于检索的重排序模型
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
和本次选用的大模型
sed -i '29s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini
修改好的配置文件应该如下图所示:

配置文件具体含义和更多细节参考 3.4 配置文件解析。
2.2 创建知识库
本示例中,使用 InternLM 的 Huixiangdou 文档作为新增知识数据检索来源,在不重新训练的情况下,打造一个 Huixiangdou 技术问答助手。
首先,下载 Huixiangdou 语料:
cd /root/huixiangdou && mkdir repodirgit clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou提取知识库特征,创建向量数据库。数据库向量化的过程应用到了 LangChain 的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型,如果没有在 config.ini 文件中指定本地模型路径,茴香豆将自动从 HuggingFace 拉取默认模型。
除了语料知识的向量数据库,茴香豆建立接受和拒答两个向量数据库,用来在检索的过程中更加精确的判断提问的相关性,这两个数据库的来源分别是:
- 接受问题列表,希望茴香豆助手回答的示例问题
- 存储在
huixiangdou/resource/good_questions.json中
- 存储在
- 拒绝问题列表,希望茴香豆助手拒答的示例问题
- 存储在
huixiangdou/resource/bad_questions.json中 - 其中多为技术无关的主题或闲聊
- 如:“nihui 是谁”, “具体在哪些位置进行修改?”, “你是谁?”, “1+1”
- 存储在
运行下面的命令,增加茴香豆相关的问题到接受问题示例中:
cd /root/huixiangdou
mv resource/good_questions.json resource/good_questions_bk.jsonecho '["mmpose中怎么调用mmyolo接口","mmpose实现姿态估计后怎么实现行为识别","mmpose执行提取关键点命令不是分为两步吗,一步是目标检测,另一步是关键点提取,我现在目标检测这部分的代码是demo/topdown_demo_with_mmdet.py demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth 现在我想把这个mmdet的checkpoints换位yolo的,那么应该怎么操作","在mmdetection中,如何同时加载两个数据集,两个dataloader","如何将mmdetection2.28.2的retinanet配置文件改为单尺度的呢?","1.MMPose_Tutorial.ipynb、inferencer_demo.py、image_demo.py、bottomup_demo.py、body3d_pose_lifter_demo.py这几个文件和topdown_demo_with_mmdet.py的区别是什么,\n2.我如果要使用mmdet是不是就只能使用topdown_demo_with_mmdet.py文件,","mmpose 测试 map 一直是 0 怎么办?","如何使用mmpose检测人体关键点?","我使用的数据集是labelme标注的,我想知道mmpose的数据集都是什么样式的,全都是单目标的数据集标注,还是里边也有多目标然后进行标注","如何生成openmmpose的c++推理脚本","mmpose","mmpose的目标检测阶段调用的模型,一定要是demo文件夹下的文件吗,有没有其他路径下的文件","mmpose可以实现行为识别吗,如果要实现的话应该怎么做","我在mmyolo的v0.6.0 (15/8/2023)更新日志里看到了他新增了支持基于 MMPose 的 YOLOX-Pose,我现在是不是只需要在mmpose/project/yolox-Pose内做出一些设置就可以,换掉demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py 改用mmyolo来进行目标检测了","mac m1从源码安装的mmpose是x86_64的","想请教一下mmpose有没有提供可以读取外接摄像头,做3d姿态并达到实时的项目呀?","huixiangdou 是什么?","使用科研仪器需要注意什么?","huixiangdou 是什么?","茴香豆 是什么?","茴香豆 能部署到微信吗?","茴香豆 怎么应用到飞书","茴香豆 能部署到微信群吗?","茴香豆 怎么应用到飞书群","huixiangdou 能部署到微信吗?","huixiangdou 怎么应用到飞书","huixiangdou 能部署到微信群吗?","huixiangdou 怎么应用到飞书群","huixiangdou","茴香豆","茴香豆 有哪些应用场景","huixiangdou 有什么用","huixiangdou 的优势有哪些?","茴香豆 已经应用的场景","huixiangdou 已经应用的场景","huixiangdou 怎么安装","茴香豆 怎么安装","茴香豆 最新版本是什么","茴香豆 支持哪些大模型","茴香豆 支持哪些通讯软件","config.ini 文件怎么配置","remote_llm_model 可以填哪些模型?"
]' > /root/huixiangdou/resource/good_questions.json再创建一个测试用的问询列表,用来测试拒答流程是否起效:
cd /root/huixiangdouecho '[
"huixiangdou 是什么?",
"你好,介绍下自己"
]' > ./test_queries.json在确定好语料来源后,运行下面的命令,创建 RAG 检索过程中使用的向量数据库:
# 创建向量数据库存储目录
cd /root/huixiangdou && mkdir workdir # 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json向量数据库的创建需要等待一小段时间,过程约占用 1.6G 显存。
完成后,Huixiangdou 相关的新增知识就以向量数据库的形式存储在 workdir 文件夹下。
检索过程中,茴香豆会将输入问题与两个列表中的问题在向量空间进行相似性比较,判断该问题是否应该回答,避免群聊过程中的问答泛滥。确定的回答的问题会利用基础模型提取关键词,在知识库中检索 top K 相似的 chunk,综合问题和检索到的 chunk 生成答案。
2.3 运行茴香豆知识助手
我们已经提取了知识库特征,并创建了对应的向量数据库。现在,让我们来测试一下效果:
命令行运行:
# 填入问题
sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py# 运行茴香豆
cd /root/huixiangdou/
python3 -m huixiangdou.main --standaloneRAG 技术的优势就是非参数化的模型调优,这里使用的仍然是基础模型 InternLM2-Chat-7B, 没有任何额外数据的训练。面对同样的问题,我们的茴香豆技术助理能够根据我们提供的数据库生成准确的答案:


InternLM2-Chat-7B 的关于 huixiangdou 问题的原始输出:

到此我们就完成了一个 茴香豆知识助手 的服务器端部署(基础作业)的全部内容。
后面可以根据自己的实际需求,学习茴香豆的进阶应用或者阅读茴香豆文档将茴香豆链接到即时通讯软件或打造自己的茴香豆 Web 版。
3 茴香豆进阶(选做)
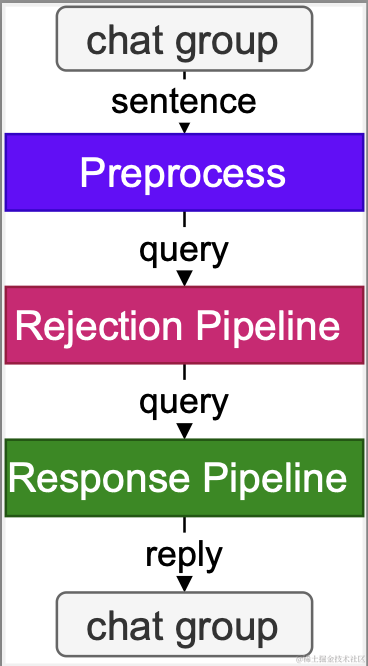
茴香豆并非单纯的 RAG 功能实现,而是一个专门针对群聊优化的知识助手,下面介绍一些茴香豆的进阶用法。详情请阅读技术报告或观看本节课理论视频。
3.1 加入网络搜索
茴香豆除了可以从本地向量数据库中检索内容进行回答,也可以加入网络的搜索结果,生成回答。
开启网络搜索功能需要用到 Serper 提供的 API:
- 登录 Serper ,注册:

- 进入 Serper API 界面,复制自己的 API-key:
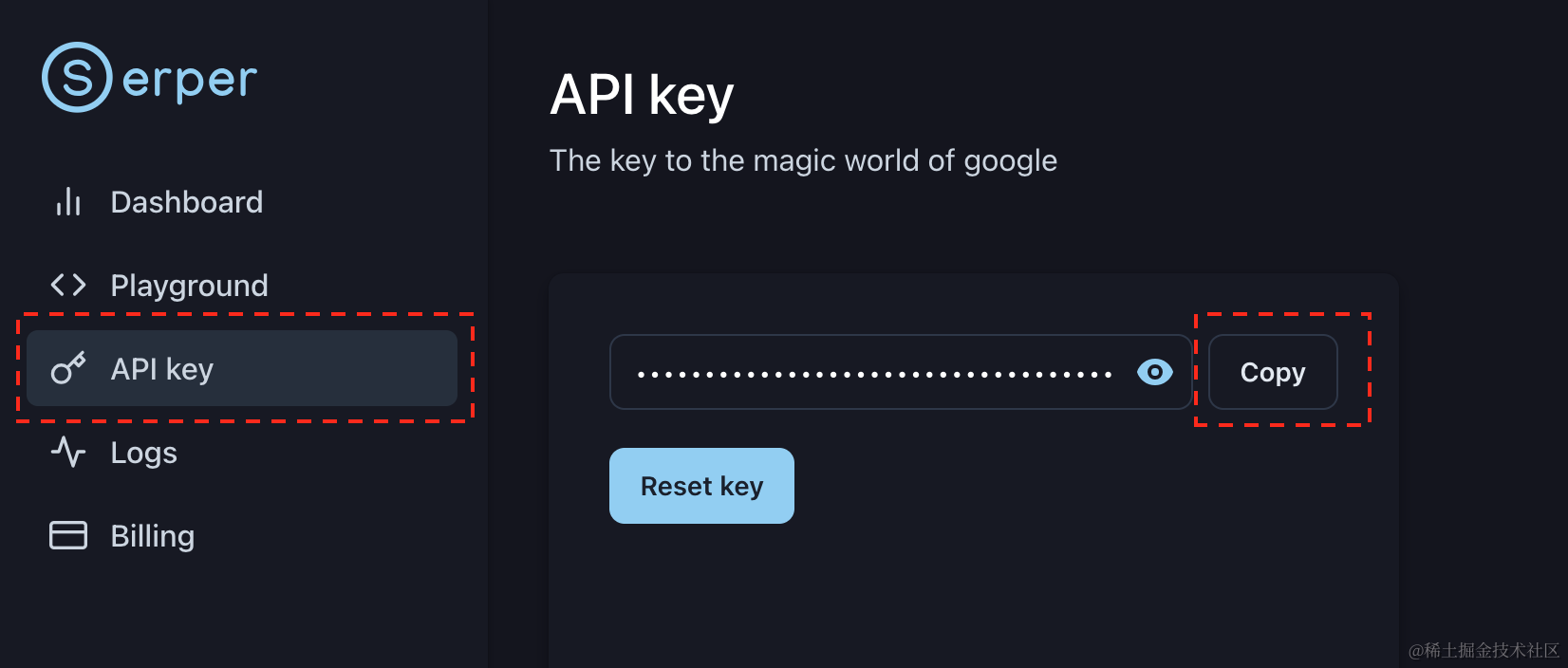
- 替换
/huixiangdou/config.ini中的 ${YOUR-API-KEY} 为自己的API-key:
[web_search]
# check https://serper.dev/api-key to get a free API key
x_api_key = "${YOUR-API-KEY}"
domain_partial_order = ["openai.com", "pytorch.org", "readthedocs.io", "nvidia.com", "stackoverflow.com", "juejin.cn", "zhuanlan.zhihu.com", "www.cnblogs.com"]
save_dir = "logs/web_search_result"
其中 domain_partial_order 可以设置网络搜索的范围。

3.2 使用远程模型
茴香豆除了可以使用本地大模型,还可以轻松的调用云端模型 API。
目前,茴香豆已经支持 Kimi,GPT-4,Deepseek 和 GLM 等常见大模型API。
想要使用远端大模型,首先修改 /huixiangdou/config.ini 文件中
enable_local = 0 # 关闭本地模型
enable_remote = 1 # 启用云端模型
接着,如下图所示,修改 remote_ 相关配置,填写 API key、模型类型等参数。

| 远端模型配置选项 | GPT | Kimi | Deepseek | ChatGLM | xi-api | alles-apin |
|---|---|---|---|---|---|---|
remote_type | gpt | kimi | deepseek | zhipuai | xi-api | alles-apin |
remote_llm_max_text_length 最大值 | 192000 | 128000 | 16000 | 128000 | 192000 | - |
remote_llm_model | “gpt-4-0613” | “moonshot-v1-128k” | “deepseek-chat” | “glm-4” | “gpt-4-0613” | - |
启用远程模型可以大大降低GPU显存需求,根据测试,采用远程模型的茴香豆应用,最小只需要2G内存即可。
需要注意的是,这里启用的远程模型,只用在问答分析和问题生成,依然需要本地嵌入、重排序模型进行特征提取。
也可以尝试同时开启 local 和 remote 模型,茴香豆将采用混合模型的方案,详见 技术报告,效果更好。
茴香豆 Web 版 在 OpenXLab 上部署了混合模型的 Demo,可上传自己的语料库测试效果。
3.3 利用 Gradio 搭建网页 Demo
让我们用 Gradio 搭建一个自己的网页对话 Demo,来看看效果。
- 首先,安装 Gradio 依赖组件:
pip install gradio==4.25.0 redis==5.0.3 flask==3.0.2 lark_oapi==1.2.4
- 运行脚本,启动茴香豆对话 Demo 服务:
cd /root/huixiangdou
python3 -m tests.test_query_gradio 此时服务器端接口已开启。如果在本地服务器使用,直接在浏览器中输入 127.0.0.1:7860 ,即可进入茴香豆对话 Demo 界面。
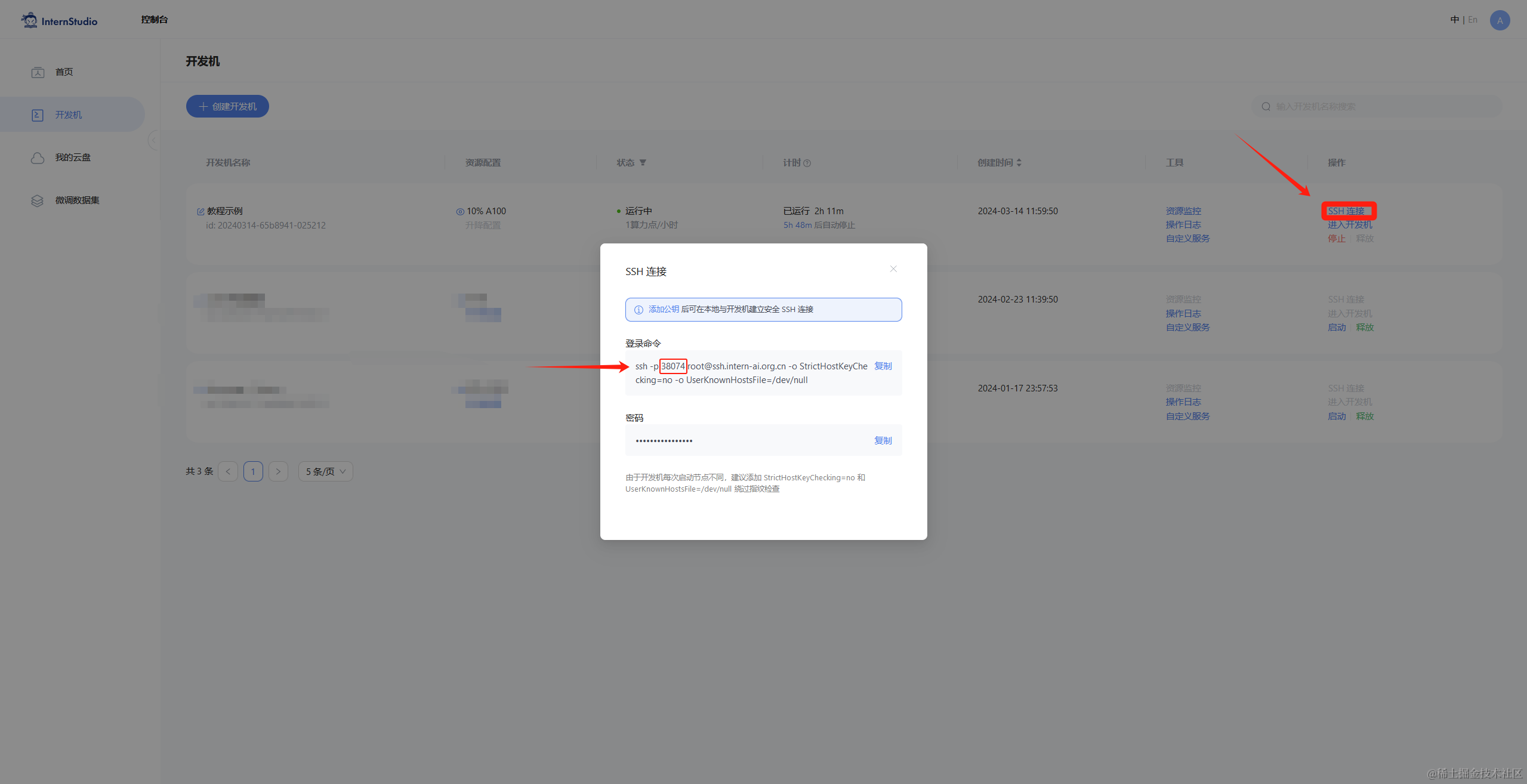
针对远程服务器,如我们的 Intern Studio 开发机,我们需要设置端口映射,转发端口到本地浏览器:
- 查询开发机端口和密码(图中端口示例为 38374):
- 在本地打开命令行工具:
- Windows 使用快捷键组合
Windows + R(Windows 即开始菜单键)打开指令界面,并输入命令Powershell,按下回车键 - Mac 用户直接找到并打开
终端 - Ubuntu 用户使用快捷键组合
ctrl + alt + t
在命令行中输入如下命令,命令行会提示输入密码:
ssh -CNg -L 7860:127.0.0.1:7860 root@ssh.intern-ai.org.cn -p <你的端口号>
- 复制开发机密码到命令行中,按回车,建立开发机到本地到端口映射。

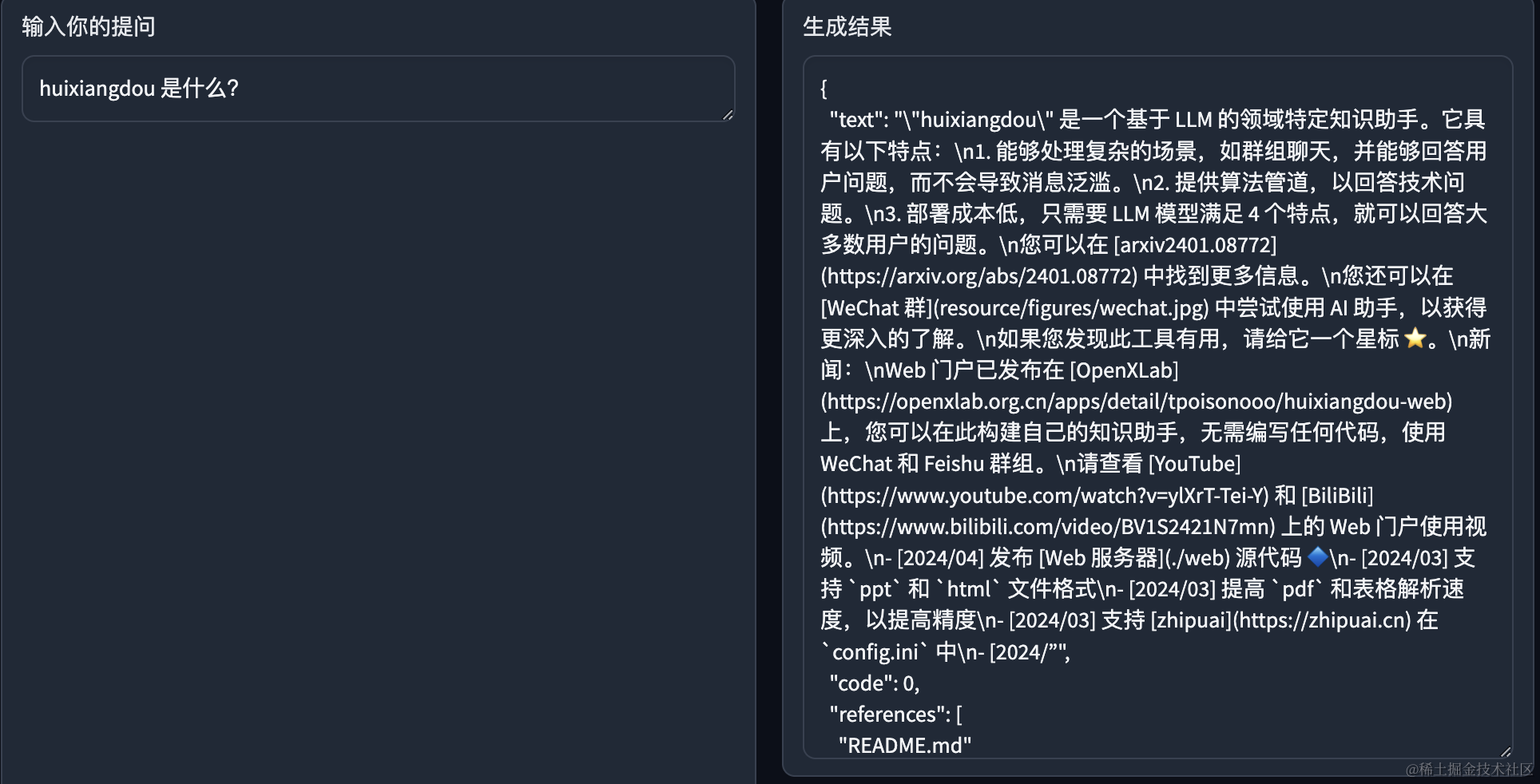
- 在本地浏览器中输入 127.0.0.1:7860 进入 Gradio 对话 Demo 界面,开始对话。
如果需要更换检索的知识领域,只需要用新的语料知识重复步骤 2.2 创建知识库 提取特征到新的向量数据库,更改 huixiangdou/config.ini 文件中 work_dir = "新向量数据库路径";
或者运行:
python3 -m tests.test_query_gradi --work_dir <新向量数据库路径>
无需重新训练或微调模型,就可以轻松的让基础模型学会新领域知识,搭建一个新的问答助手。
3.4 配置文件解析
茴香豆的配置文件位于代码主目录下,采用 Toml 形式,有着丰富的功能,下面将解析配置文件中重要的常用参数。
[feature_store]
...
reject_throttle = 0.22742061846268935
...
embedding_model_path = "/root/models/bce-embedding-base_v1"
reranker_model_path = "/root/models/bce-reranker-base_v1"
...
work_dir = "workdir"
reject_throttle: 拒答阈值,0-1,数值越大,回答的问题相关性越高。拒答分数在检索过程中通过与示例问题的相似性检索得出,高质量的问题得分高,无关、低质量的问题得分低。只有得分数大于拒答阈值的才会被视为相关问题,用于回答的生成。当闲聊或无关问题较多的环境可以适当调高。
embedding_model_path 和 reranker_model_path: 嵌入和重排用到的模型路径。不设置本地模型路径情况下,默认自动通过 Huggingface 下载。开始自动下载前,需要使用下列命令登录 Huggingface 账户获取权限:
huggingface-cli login
work_dir: 向量数据库路径。茴香豆安装后,可以通过切换向量数据库路径,来回答不同知识领域的问答。
[llm.server]
...
local_llm_path = "/root/models/internlm2-chat-1_8b"
local_llm_max_text_length = 3000
...
local_llm_path: 本地模型文件夹路径或模型名称。现支持 书生·浦语 和 通义千问 模型类型,调用 transformers 的 AutoModels 模块,除了模型路径,输入 Huggingface 上的模型名称,如*“internlm/internlm2-chat-7b”、“qwen/qwen-7b-chat-int8”、“internlm/internlm2-chat-20b”*,也可自动拉取模型文件。
local_llm_max_text_length: 模型可接受最大文本长度。
远端模型支持参考上一小节。
[worker]
# enable search enhancement or not
enable_sg_search = 0
save_path = "logs/work.txt"
...
[worker]: 增强搜索功能,配合 [sg_search] 使用。增强搜索利用知识领域的源文件建立图数据库,当模型判断问题为无关问题或回答失败时,增强搜索功能将利用 LLM 提取的关键词在该图数据库中搜索,并尝试用搜索到的内容重新生成答案。在 config.ini 中查看 [sg_search] 具体配置示例。
[worker.time]
start = "00:00:00"
end = "23:59:59"
has_weekday = 1
[worker.time]: 可以设置茴香豆每天的工作时间,通过 start 和 end 设定应答的起始和结束时间。
has_weekday: = 1 的时候,周末不应答😂(豆哥拒绝 996)。
[frontend]
...
[fronted]: 前端交互设置。茴香豆代码仓库 查看具体教程。
3.5 文件结构
通过了解主要文件的位置和作用,可以更好的理解茴香豆的工作原理。
.
├── LICENSE
├── README.md
├── README_zh.md
├── android
├── app.py
├── config-2G.ini
├── config-advanced.ini
├── config-experience.ini
├── config.ini # 配置文件
├── docs # 教学文档
├── huixiangdou # 存放茴香豆主要代码,重点学习
├── huixiangdou-inside.md
├── logs
├── repodir # 默认存放个人数据库原始文件,用户建立
├── requirements-lark-group.txt
├── requirements.txt
├── resource
├── setup.py
├── tests # 单元测试
├── web # 存放茴香豆 Web 版代码
└── web.log
└── workdir # 默认存放茴香豆本地向量数据库,用户建立
./huixiangdou
├── __init__.py
├── frontend # 存放茴香豆前端与用户端和通讯软件交互代码
│ ├── __init__.py
│ ├── lark.py
│ └── lark_group.py
├── main.py # 运行主贷
├── service # 存放茴香豆后端工作流代码
│ ├── __init__.py
│ ├── config.py #
│ ├── feature_store.py # 数据嵌入、特征提取代码
│ ├── file_operation.py
│ ├── helper.py
│ ├── llm_client.py
│ ├── llm_server_hybrid.py # 混合模型代码
│ ├── retriever.py # 检索模块代码
│ ├── sg_search.py # 增强搜索,图检索代码
│ ├── web_search.py # 网页搜索代码
│ └── worker.py # 主流程代码
└── version.py
茴香豆工作流中用到的 Prompt 位于 huixiangdou/service/worker.py 中。可以根据业务需求尝试调整 Prompt,打造你独有的茴香豆知识助手。
...# Switch languages according to the scenario.if self.language == 'zh':self.TOPIC_TEMPLATE = '告诉我这句话的主题,直接说主题不要解释:“{}”'self.SCORING_QUESTION_TEMPLTE = '“{}”\n请仔细阅读以上内容,判断句子是否是个有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。\n判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释。' # noqa E501self.SCORING_RELAVANCE_TEMPLATE = '问题:“{}”\n材料:“{}”\n请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。\n' # noqa E501self.KEYWORDS_TEMPLATE = '谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。搜索参数类型 string, 内容是短语或关键字,以空格分隔。\n你现在是{}交流群里的技术助手,用户问“{}”,你打算通过谷歌搜索查询相关资料,请提供用于搜索的关键字或短语,不要解释直接给出关键字或短语。' # noqa E501self.SECURITY_TEMAPLTE = '判断以下句子是否涉及政治、辱骂、色情、恐暴、宗教、网络暴力、种族歧视等违禁内容,结果用 0~10 表示,不要解释直接给出得分。判断标准:涉其中任一问题直接得 10 分;完全不涉及得 0 分。直接给得分不要解释:“{}”' # noqa E501self.PERPLESITY_TEMPLATE = '“question:{} answer:{}”\n阅读以上对话,answer 是否在表达自己不知道,回答越全面得分越少,用0~10表示,不要解释直接给出得分。\n判断标准:准确回答问题得 0 分;答案详尽得 1 分;知道部分答案但有不确定信息得 8 分;知道小部分答案但推荐求助其他人得 9 分;不知道任何答案直接推荐求助别人得 10 分。直接打分不要解释。' # noqa E501self.SUMMARIZE_TEMPLATE = '{} \n 仔细阅读以上内容,总结得简短有力点' # noqa E501# self.GENERATE_TEMPLATE = '材料:“{}”\n 问题:“{}” \n 请仔细阅读参考材料回答问题,材料可能和问题无关。如果材料和问题无关,尝试用你自己的理解来回答问题。如果无法确定答案,直接回答不知道。' # noqa E501self.GENERATE_TEMPLATE = '材料:“{}”\n 问题:“{}” \n 请仔细阅读参考材料回答问题。' # noqa E501
...
作业
基础作业 - 完成下面两个作业
1. 在茴香豆 Web 版中创建自己领域的知识问答助手
- 参考视频零编程玩转大模型,学习茴香豆部署群聊助手
- 完成不少于 400 字的笔记 + 线上茴香豆助手对话截图(不少于5轮)
- (可选)参考 代码 在自己的服务器部署茴香豆 Web 版
2.在 InternLM Studio 上部署茴香豆技术助手
- 根据教程文档搭建
茴香豆技术助手,针对问题"茴香豆怎么部署到微信群?"进行提问 - 完成不少于 400 字的笔记 + 截图
进阶作业 - 二选一
A.【应用方向】 结合自己擅长的领域知识(游戏、法律、电子等)、专业背景,搭建个人工作助手或者垂直领域问答助手,参考茴香豆官方文档,部署到下列任一平台。
- 飞书、微信
- 可以使用 茴香豆 Web 版 或 InternLM Studio 云端服务器部署
- 涵盖部署全过程的作业报告和个人助手问答截图
B.【算法方向】尝试修改 good_questions.json、调试 prompt 或应用其他 NLP 技术,如其他 chunk 方法,提高个人工作助手的表现。
- 完成不少于 400 字的笔记 ,记录自己的尝试和调试思路,涵盖全过程和改进效果截图
大作业项目选题
A.【工程方向】 参与贡献茴香豆前端,将茴香豆助手部署到下列平台
- Github issue、Discord、钉钉、X
B.【应用方向】 茴香豆RAG-Agent
- 应用茴香豆建立一个 ROS2 的机器人Agent
C.【算法方向】 茴香豆多模态
- 参与茴香豆多模态的工作
相关文章:
【InternLM 实战营第二期-笔记3】茴香豆:搭建你的 RAG 智能助理
书生浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,很高兴能参与本次第二期训练营,我也将会通过笔记博客的方式记录学习的过程与遇到的问题,并为代码添加注释,希望可以帮助到你们。 记得点赞哟(๑ゝω╹๑) 茴香豆:搭建…...

Advanced RAG 03:运用 RAGAs 与 LlamaIndex 评估 RAG 应用
编者按:目前,检索增强生成(Retrieval Augmented Generation,RAG)技术已经广泛使用于各种大模型应用场景。然而,如何准确评估 RAG 系统的性能和效果,一直是业界和学界共同关注的重点问题。若无法…...

leetcode
找到字符串中所有字母异位词 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 异位词 指由相同字母重排列形成的字符串(包括相同的字符串) 示例 1: 输入: s "…...
Unity DOTS《群体战斗弹幕游戏》核心技术分析之3D角色动画
最近DOTS发布了正式的版本, 我们来分享现在流行基于群体战斗的弹幕类游戏,实现的核心原理。今天给大家介绍大规模战斗群体3D角色的动画如何来实现。 DOTS 对角色动画支持的局限性 截止到Unity DOTS发布的版本1.0.16,目前还是无法很好的支持3D角色动画。在DOTS 的ba…...
react异步组件如何定义使用 标准使用方法
目录 默认导出和命名导出的格式 默认导出的组件 使用方式 命名导出的组件 使用方式 默认导出和命名导出的格式 默认导出: // person.js const person {name: Alice,age: 30 };export default person;命名导出: // math.js export const add (a, b) > a b; exp…...
React + Ts + Vite + Antd 项目搭建
1、创建项目 npm create vite 项目名称 选择 react 选择 typescript 关闭严格模式 建议关闭严格模式,因为不能自动检测副作用,有意双重调用。将严格模式注释即可。 2、配置sass npm install sass 更换所有后缀css为sass vite.config.ts中注册全局样式 /…...

js爬虫puppeteer库 解决网页动态渲染无法爬取
我们爬取这个网址上面的股票实时部分宇通客车(600066)_股票价格_行情_走势图—东方财富网 我们用正常的方法爬取会发现爬取不下来,是因为这个网页这里是实时渲染的,我们直接通过网址接口访问这里还没有渲染出来 于是我们可以通过下面的代码来进行爬取: …...

代码随想录:二叉树5
目录 102.二叉树的层序遍历 题目 代码(队列实现) 107.二叉树的层序遍历II 题目 代码 199.二叉树的右视图 题目 代码 637.二叉树的层平均值 题目 代码 102.二叉树的层序遍历 题目 给你二叉树的根节点 root ,返回其节点值的 层序遍…...

Tomcat 获取客户端真实IP X-Forwarded-For
Tomcat 获取客户端真实IP X-Forwarded-For 代码实现: 在Host标签下面添加代码: <Valve className"org.apache.catalina.valves.RemoteIpValve" remoteIpHeader"x-forwarded-for" remoteIpProxiesHeader"x-forwarded-by&q…...
记录PS学习查漏补缺
PS学习 PS学习理论快捷键抠图PS专属多软件通用快捷键 PS学习 理论 JPEG (不带透明通道) PNG (带透明通道) 快捷键 抠图 抠图方式 魔棒工具 反选选中区域 CtrlShiftI(反选) 钢笔抠图注意事项 按着Ctrl单击节点 会出现当前节…...
Kafka 架构深入探索
目录 一、Kafka 工作流程及文件存储机制 二、数据可靠性保证 三 、数据一致性问题 3.1follower 故障 3.2leader 故障 四、ack 应答机制 五、部署FilebeatKafkaELK 5.1环境准备 5.2部署ELK 5.2.1部署 Elasticsearch 软件 5.2.1.1修改elasticsearch主配置文件 5.2…...
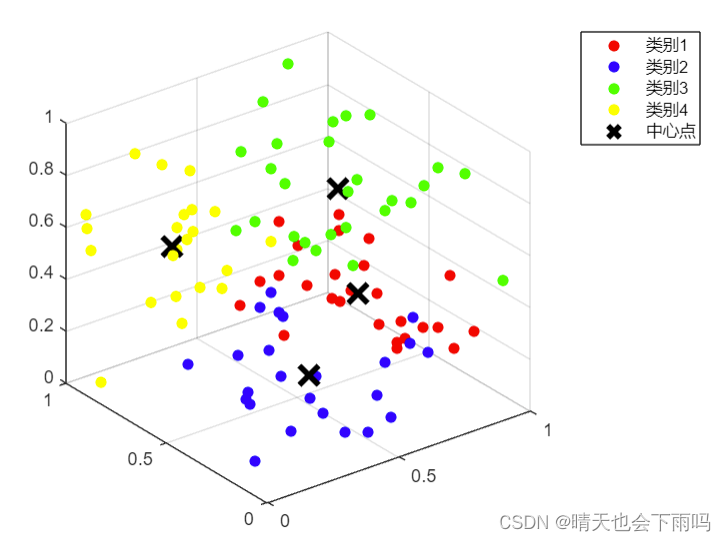
k-means聚类算法的MATLAB实现及可视化
K-means算法是一种无监督学习算法,主要用于数据聚类。其工作原理基于迭代优化,将数据点划分为K个集群,使得每个数据点都属于最近的集群,并且每个集群的中心(质心)是所有属于该集群的数据点的平均值。以下是…...
Excel文件转Asc文件
单个转换 import os import pandas as pdfilename (10)result01-1.xlsx df pd.read_excel(filename) # 读取Excel文件# 将数据保存为ASC格式 asc_filename os.path.splitext(filename)[0] .asc # 获取文件名并替换扩展名 with open(asc_filename, w) as file:# 写入文件…...
【题目】【信息安全管理与评估】2022年国赛高职组“信息安全管理与评估”赛项样题7
【题目】【信息安全管理与评估】2022年国赛高职组“信息安全管理与评估”赛项样题7 信息安全管理与评估 网络系统管理 网络搭建与应用 云计算 软件测试 移动应用开发 任务书,赛题,解析等资料,知识点培训服务 添加博主wx:liuliu548…...
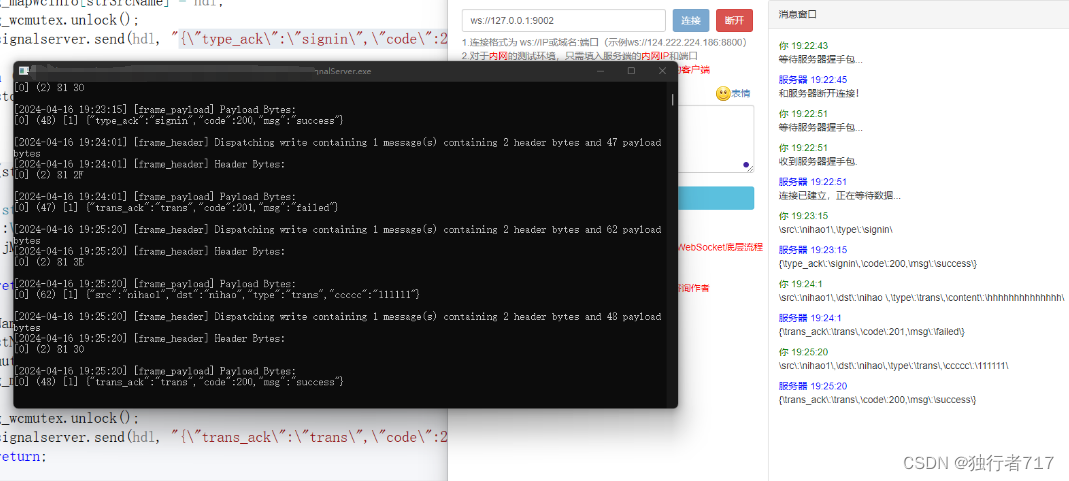
Webrtc 信令服务器实现
webrtc建联流程图 由上图可知,所谓的信令服务器其实就是将peer的offer/candidate/answer传给对端而已。这样的话实现方式就有很多种了,目前普遍的方式HTTP/HTTPS,WS/WSS。像webrtc-demo-peerconnection就是实现HTTP这种方式。本文使用WS&…...
【Blockchain】连接智能合约与现实世界的桥梁Chainlink
去中心化预言机试图实现依赖因果关系而不是个人关系的去信任和确定性结果。它以与区块链网络相同的方式实现这些结果,即在许多网络参与者之间分配信任。通过利用许多不同的数据源并实施不受单个实体控制的预言机系统,去中心化的预言机网络有可能为智能合…...

解决EasyPoi导入Excel获取不到第一列的问题
文章目录 1. 复现错误2. 分析错误2.1 导入的代码2.2 DictExcel实体类2.2 表头和标题3. 解决问题1. 复现错误 使用EasyPoi导入数据时,Excel表格如下图: 但在导入时,出现如下错误: name为英文名称,在第一列,Excel表格有值,但导入的代码中为null,就很奇怪? 2. 分析错误 …...
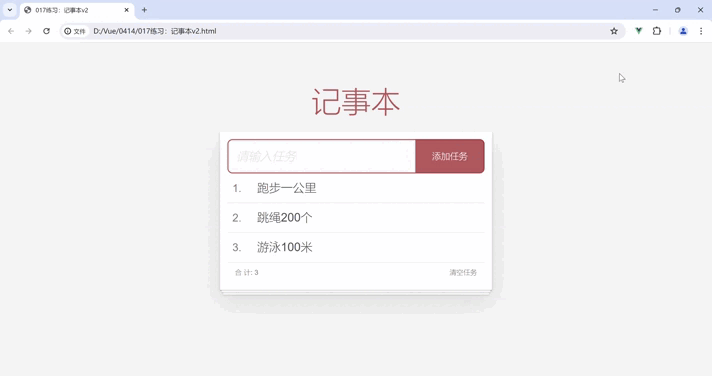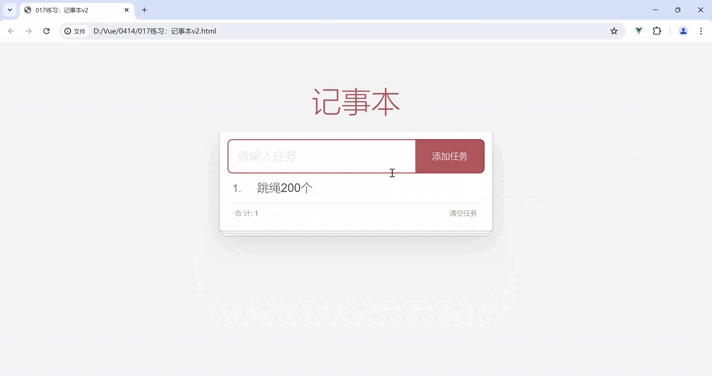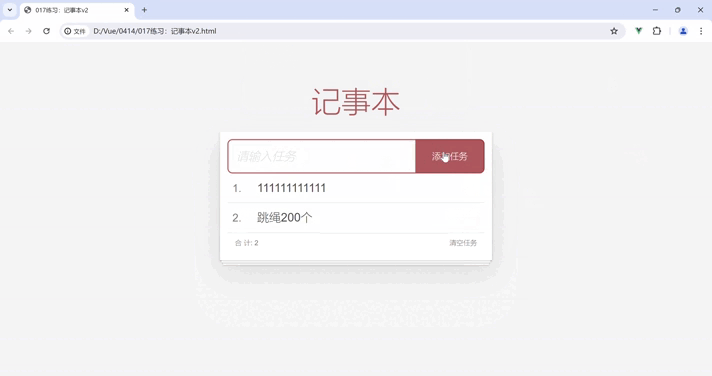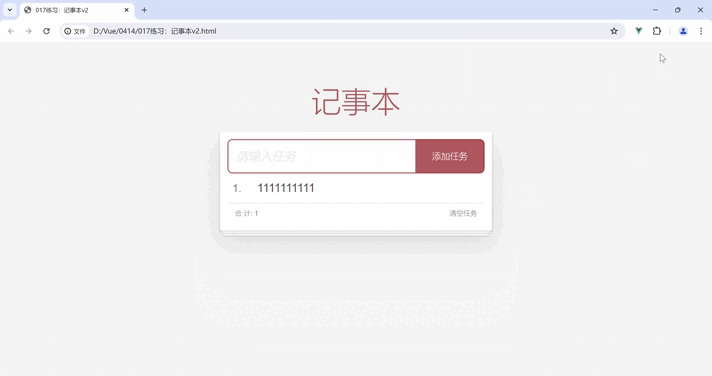
Vue 阶段练习:记事本
将 Vue快速入门 和 Vue 指令的学习成果应用到实际场景中(如该练习 记事本),我们能够解决实际问题并提升对 Vue 的技能掌握。 目录 功能展示 需求分析 我的代码 案例代码 知识点总结 功能展示 需求分析 列表渲染删除功能添加功能底部统计…...
JavaScript判断受访域名,调用不同的js文件
比如:我有三个域名: ① dengoo.net ② jfzm.cc ③ ceeha.com 如果当前访问的是 dengoo.net 域名及域名下页面,则调用 a.js 如果当前访问的是 jfzm.cc 域名及域名下页面,则调用 b.js 如果当前访问的是 ceeha.com 域名及域名下…...
下载软件时的Ubuntu x86_64-v2、skylake、aarch64版本分别代表什么?
Ubuntu-x86_64-v2、Ubuntu-x86_64-skylake和Ubuntu-aarch64都是Ubuntu的不同版本或变种,它们之间的主要区别在于所支持的硬件架构和针对特定硬件的优化。 Ubuntu-x86_64-v2: 这是基于x86_64(也称为AMD64或Intel 64)架构的Ubuntu版…...

数字化社交的引擎:解析Facebook的影响力
Facebook,作为全球最大的社交媒体平台,已经深深地融入了我们的日常生活和文化中。它不仅仅是一个简单的社交工具,更是一个复杂的数字生态系统,影响着我们的社交模式、文化认同以及信息获取方式。在这篇文章中,我们将深…...
淘宝API商品详情数据在数据分析行业中具有不可忽视的重要性
淘宝商品详情数据在数据分析行业中具有不可忽视的重要性。这些数据为商家、市场分析师以及数据科学家提供了丰富的信息,有助于他们更深入地理解市场动态、消费者行为以及商品竞争态势。以下是淘宝商品详情数据在数据分析行业中的重要性体现: 请求示例&a…...

【产品】ANET智能通信管理机 物联网网关 电力监控/能耗监测/能源管理系统
产品概述 本系列智能通信管理机是一款采用嵌入式硬件计算机平台,具有多个下行通信接口及一个或者多个上行网络接口,用于将一个目标区域内所有的智能监控/保护装置的通信数据整理汇总后,实时上传主站系统,完成遥信、遥测等能源数据…...
R语言数据分析案例
在R语言中进行数据分析通常涉及数据的导入、清洗、探索、建模和可视化等步骤。以下是一个简化的案例,展示了如何使用R语言进行数据分析: 1. 数据导入 首先,你需要将数据导入R环境中。这可以通过多种方式完成,例如使用read.csv()…...
vscode debug 配置:launch.json
打开新项目左边的“运行和调试” 点击蓝色字体“创建 launch.json 文件” 选择上方“python” 选择“Python 文件 调试当前正在运行的Python文件” 配置launch.json文件内容: {// 使用 IntelliSense 了解相关属性// 悬停以查看现有属性的描述。// 欲了解更多信息&a…...
idea工具使用Tomcat创建jsp 部署servlet到服务器
使用tomcat创建jsp 在tomcat官网中下载对应windows版本的tomcat文件 Apache Tomcat - Welcome! 解压到系统目录中,记得不要有中文路径 新建一个java项目 点击右上角 点击加号 找到Tomcat Service的 Local 点击右下角的Fix一下,然后ok关闭 再重新打开一…...

MyBatisPlus自定义SQL
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉🍎个人主页:Leo的博客💞当前专栏: 循序渐进学SpringBoot ✨特色专栏: MySQL学习 🥭本文内容:MyBatisPlus自定义SQL 📚个人知识库: Leo知识库,欢迎大家访问 目录 1.前言☕…...
使用formio和react实现在线表单设计
formiojs 是一个开源的在线表单设计工具,今天看看怎样在 react js 中使用 formiojs。 首先创建一个react工程 npx create-react-app my-react-formio-app安装依赖 cd my-react-formio-app npm install formio/react npm install formio/js另外,考虑样…...
MySQL 基础使用
文章目录 一、Navicat 工具链接 Mysql二、数据库的使用1.常用数据类型2. 建表 create3. 删表 drop4. insert 插入数据5. select 查询数据6. update 修改数据7. delete 删除记录truncate table 删除数据 三、字段约束字段1. 主键 自增delete和truncate自增长字段的影响 2. 非空…...

✌粤嵌—2024/4/3—合并K个升序链表✌
代码实现: /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* merge(struct ListNode *l1, struct ListNode *l2) {if (l1 NULL) {return l2;}if (l2 NULL) {return l1;}struct Lis…...
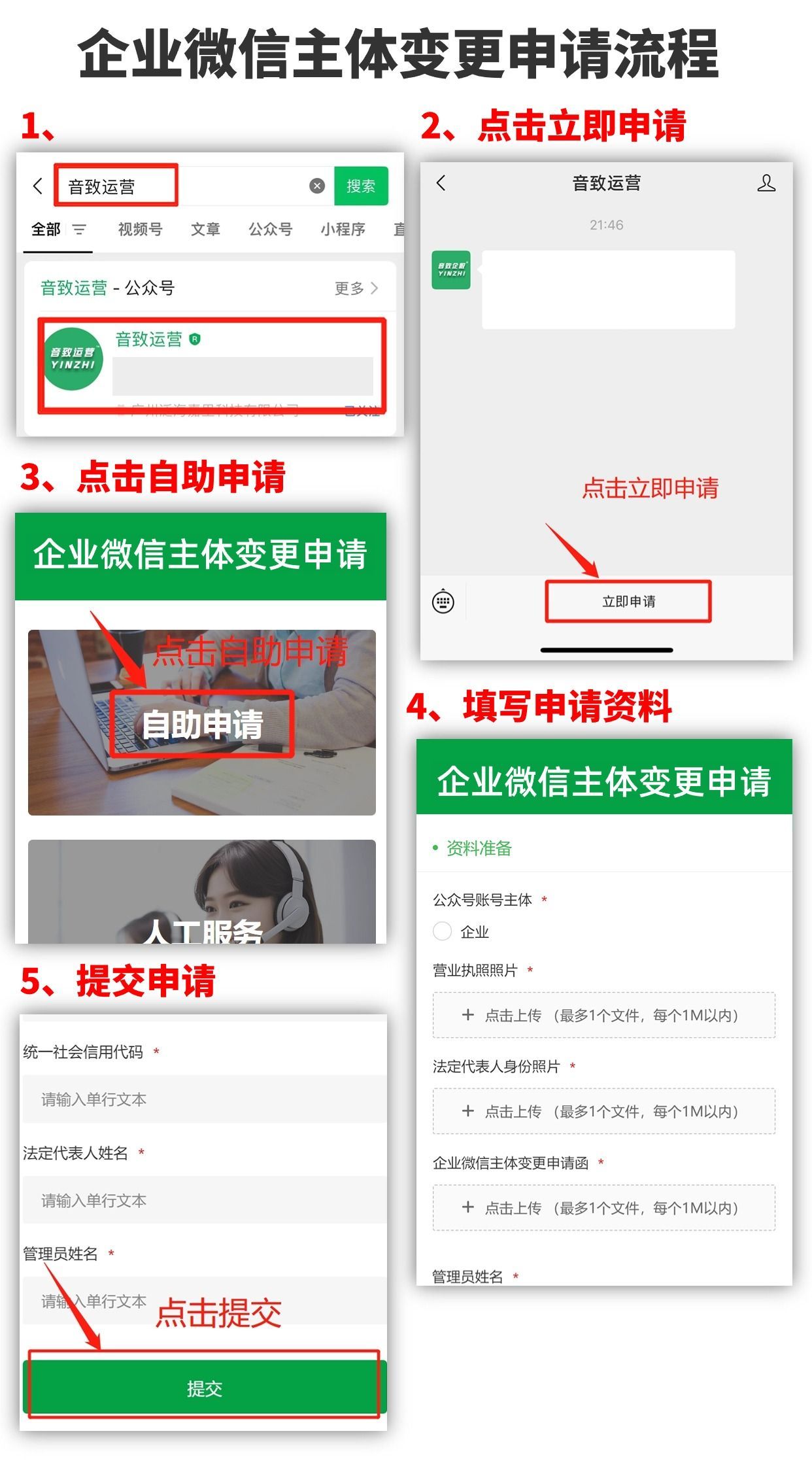
企业微信主体的修改方法
企业微信变更主体有什么作用?当我们的企业因为各种原因需要注销或已经注销,或者运营变更等情况,企业微信无法继续使用原主体继续使用时,可以申请企业主体变更,变更为新的主体。企业微信变更主体的条件有哪些࿱…...
C++的封装(十):数据和代码分离
封装的好处当然是非常多的。就不一一例举了。但封装也制造了访问壁垒。如果你是初学者,当你面对一堆封装好的C类一筹莫展,不知道从哪里下手时… 可以试试这个方法,数据和代码分离。 就是说,class只写方法,数据都放到…...

第十五届蓝桥杯大赛软件赛省赛 C/C++ 大学 B 组(基础题)
试题 C: 好数 时间限制 : 1.0s 内存限制: 256.0MB 本题总分:10 分 【问题描述】 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位 )上 的数字是奇数,偶数位(十位、千位、十万位 &…...

模板的进阶
目录 非类型模板参数 C11的静态数组容器-array 按需实例化 模板的特化 函数模板特化 类模板特化 全特化与偏特化 模板的分离编译 总结 非类型模板参数 基本概念:模板参数类型分为类类型模板参数和非类类型模板参数 类类型模板参数:跟在class…...
微服务中Dubbo通俗易懂讲解及代码实现
当你在微服务架构中需要不同服务之间进行远程通信时,Dubbo是一个优秀的选择。Dubbo是一个高性能的Java RPC框架,它提供了服务注册、发现、调用、负载均衡等功能,使得微服务之间的通信变得简单而高效。 让我们来看一下Dubbo的通俗易懂的解释和…...
Unity HDRP Release-Notes
🌈HDRP Release-Notes 收集的最近几年 Unity各个版本中 HDRP的更新内容 信息收集来自自动搜集工具👈 💡HDRP Release-Notes 2023 💡HDRP Release-Notes 2022 💡HDRP Release-Notes 2021...

Chrome将网页保存为PDF的实战教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
zotero7+Chat GPT实现ai自动阅读论文
关于这一部分的内容我在哔哩哔哩上发布了视频教程 视频链接见: zotero7GPT AI快速阅读文献_哔哩哔哩_bilibili 相关下载的官方链接如下: 1、zotero7 测试版官方下载链接: https://www.zotero.org/support/beta_builds 2、 InfiniCLOUD 云…...
STM32外设配置以及一些小bug总结
USART RX的DMA配置 这里以UART串口1为例,首先点ADD添加RX和TX配置DMA,然后模式一般会选择是normal,这个模式是当DMA的计数器减到0的时候就不做任何动作了,还有一种循环模式,是计数器减到0之后,计数器自动重…...
【数据结构与算法】:10道链表经典OJ
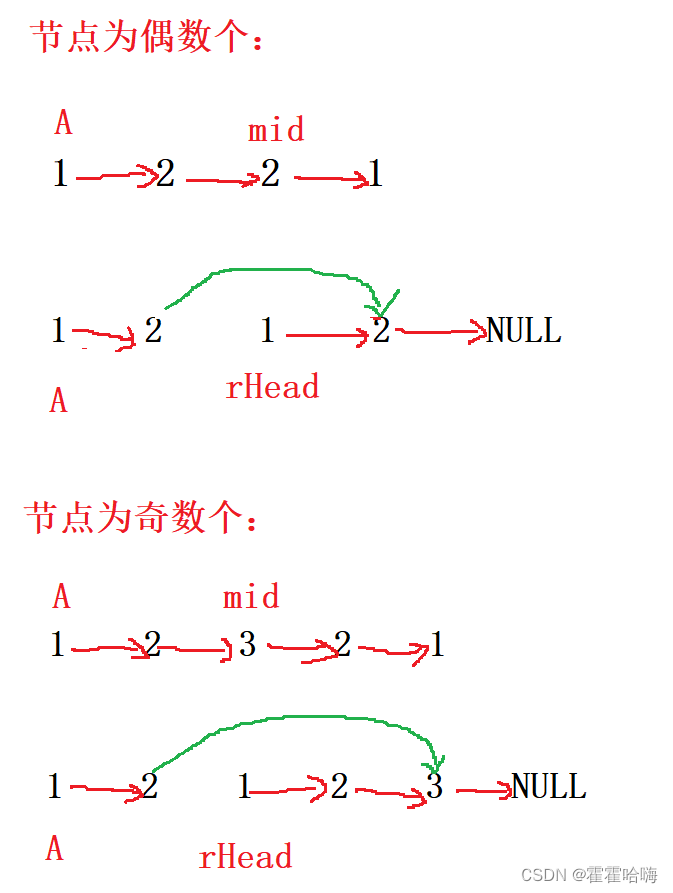
目录 1. 移除链表元素2. 反转链表2.1反转指针法2.2 头插法 3. 合并两个有序链表4. 分隔链表5. 环形链表6. 链表的中间节点7. 链表中倒数第K个节点8. 相交链表9. 环形链表的约瑟夫问题10. 链表的回文结构 1. 移除链表元素 思路1:遍历原链表,将 val 所在的…...

Python SQL解析和转换库之sqlglot使用详解
概要 Python SQLGlot是一个基于Python的SQL解析和转换库,可以帮助开发者更加灵活地处理和操作SQL语句。本文将介绍SQLGlot库的安装、特性、基本功能、高级功能、实际应用场景等方面。 安装 安装SQLGlot库非常简单,可以使用pip命令进行安装: pip install sqlglot安装完成后…...
NULL—0—nullptr 三者关系
1.概述 NULL,0,nullptr值都是0,但是类型不同,但是由于C头文件中NULL定义宏混乱,可能是int 0,也可能是(void*)0; 所以在C11及以后的标准中引入新的空指针nullptr,nullptr就是(void*)0ÿ…...
Nginx 请求的 匹配规则 与 转发规则
博文目录 文章目录 URL 与 URI匹配规则案例说明 转发规则响应静态资源案例说明 转发动态代理案例说明案例说明 URL 与 URI 通常, 一个 URL 由以下部分组成 scheme://host:port/path?query#fragment scheme: 协议, 如 http, https, ftp 等host; 主机名或 IP 地址post: 端口…...

OWASP发布10大开源软件风险清单
3月20日,xz-utils 项目被爆植入后门震惊了整个开源社区,2021 年 Apache Log4j 漏洞事件依旧历历在目。倘若该后门未被及时发现,那么将很有可能成为影响最大的软件供应链漏洞之一。近几年爆发的一系列供应链漏洞和风险,使得“加强开…...

大学生前端学习第一天:了解前端
引言: 哈喽,各位大学生们,大家好呀,在本篇博客,我们将引入一个新的板块学习,那就是前端,关于前端,GPT是这样描述的:前端通常指的是Web开发中用户界面的部分,…...
公安机关人民警察证照片采集规范及自拍制作电子版指南
在当今社会,证件照的拍摄已成为我们生活中不可或缺的一部分。无论是办理身份证、驾驶证还是护照,一张规范的证件照都是必需的。而对于公安机关的人民警察来说,证件照片的采集更是有着严格的规范和要求。本文将为您详细介绍公安机关人民警察证…...
使用Python插入100万条数据到MySQL数据库并将数据逐步写出到多个Excel
Python插入100万条数据到MySQL数据库 步骤一:导入所需模块和库 首先,我们需要导入 MySQL 连接器模块和 Faker 模块。MySQL 连接器模块用于连接到 MySQL 数据库,而 Faker 模块用于生成虚假数据。 import mysql.connector # 导入 MySQL 连接…...
【备忘录】openssl记录
openssl genrsa -out ca.key 2048 openssl req -x509 -new -nodes -key ca.key -days 10000 -out ca.crt -subj “/CCN/STBeijing/LBeijing/Okubernetes/OUKubernetes-manual/CNkubernetes-ca” openssl genrsa -out etcd-ca.key 2048 openssl req -x509 -new -nodes -key etc…...
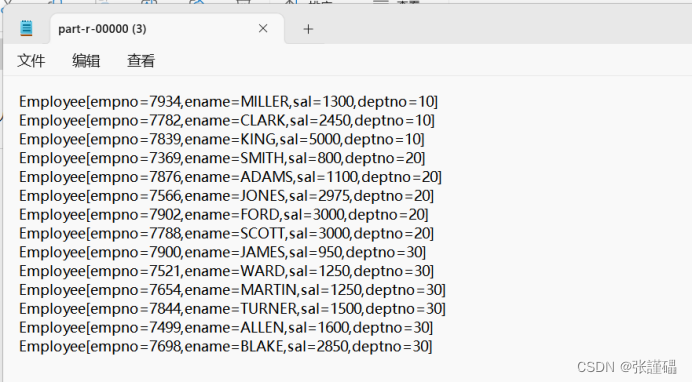
hadoop编程之工资序列化排序
数据集展示 7369SMITHCLERK79021980/12/17800207499ALLENSALESMAN76981981/2/201600300307521WARDSALESMAN76981981/2/221250500307566JONESMANAGER78391981/4/22975207654MARTINSALESMAN76981981/9/2812501400307698BLAKEMANAGER78391981/5/12850307782CLARKMANAGER78391981/…...
OpenXR手部跟踪接口与VIVE OpenXR扩展详细解析
随着虚拟现实技术的发展,手部跟踪已成为提高沉浸感和交互性的关键技术。OpenXR标准为开发者提供了一套手部跟踪的扩展接口,特别是针对VIVE设备的特定实现。以下是这些接口和类的详细解释: 1. VIVE.OpenXR.Hand VIVE.OpenXR.Hand 是HTC VIVE…...